If content has been pasted into your project from a Microsoft Office application or some other formatted source such as web page, then its underlying formatting is also pasted along with the text. You can see these formatting tags via the Code tab in the HTML editor. These formatting tags override the export template and may cause your content to look different from what you expect of the template. If you need globally clean *all* the text of your project the Global Clean options (Topics, Media captions and Glossary terms) will enable this.
The Clean HTML function is designed to remove most Microsoft applications HTML formatting, leaving the equivalent styling where possible, but without the use of embedded styles. This will leave the formatted content looking similar to “plain text” in the editor, but will generally look much better in the exported format once the template has been applied.
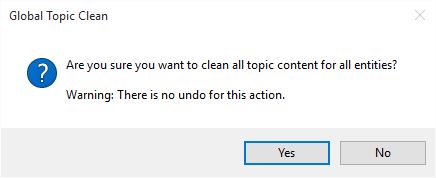
Global Topic Clean
The Global Topic Clean option is available by the main interface menu ‘Edit…Global Topic Clean‘.
This option will clean all entity topics.
Global Media Captions Clean
The Global Caption Clean option is available via the Media Manager menu ‘Media…Global Caption Clean‘
This option will clean all media captions, including library and derived caption text.
Global Glossary Terms Clean
The Global Glossary Terms Clean option is available via the Glossary Manager menu ‘Terms…Global Terms Clean‘ .
This option will clean all glossary terms, across all glossary subsets.
Tip
You should always do a test export of your fact sheets after a Global clean to review the formatting changes as some minor formatting may be required.
Import Content (HTML, MS Word or Lucid) interface.
The Import content (HTML, MS Word or Lucid data) option will allow you define a set of rules for each Project Topic that will attempt to match existing content in either HTML MS Word documents or a Lucid key and then import this into the Fact Sheet Fusion project. Each topic can have it’s own set of rules that define what to look for as well as what to exclude. The HTML and Lucid import options also support importing of images and their captions.
Important Tip
Defining sets of rules that work well across lots of existing content can be tricky, especially if you haven't done this type of operation in the past. It is highly recommended that you try out your import rules into a new database and project before attempting to import into an existing project that already contains content. This will allow you to easily check your results. It is also worth checking the imported topics code tab in the editor to ensure you are removing any undesirable formatting tags or unclosed tags. Another way to check the import success is to of course perform an export of the entities to view the resulting fact sheets. This again will help determine if your rules captured everything you need from the source documents.
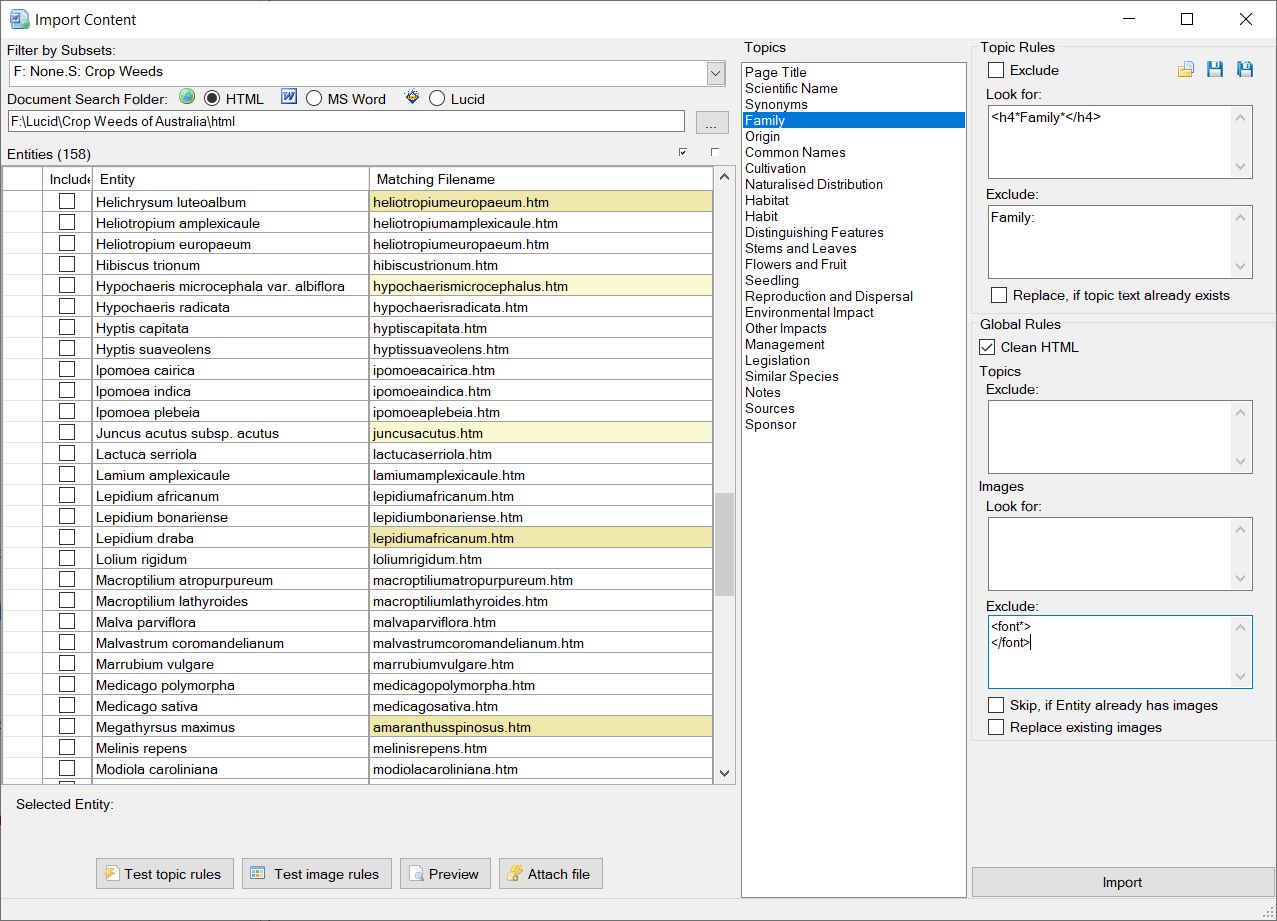
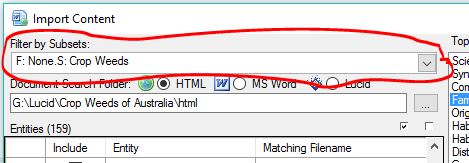
The first step in undertaking an import is to define the Entities you wish to import content for. These entities must already exist within your project. New Entities cannot be added via the Import dialog. Filtering of Entities can be done via the Filter by Subsets option located top left of the Import dialog. Entities can also be easily excluded from the import process by simply not selecting them to be included in the import process via the check box in the Include column. More information on this is detailed further below in Step 3.
Step 2.
Define import document type
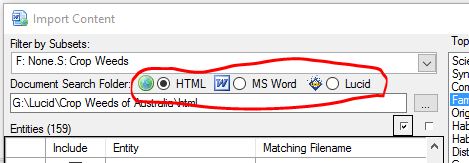
Select the document format are trying to importing from. I.e. HTML, MS Word or a supported Lucid key or data file.
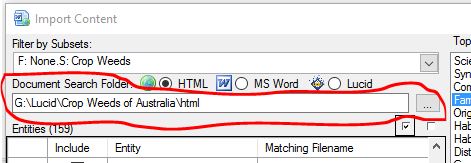
Step 3.
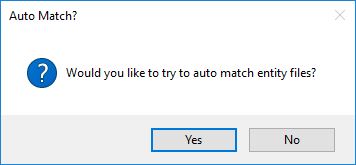
Use the document folder browse button to select the folder where the HTML, MS Word documents or Lucid key or data files are located. Once a valid folder or Lucid key file has been defined, the content importer will as if you wish to auto match the entities by scanning the folder or key for matching document types (HTML: .htm, .html or MS Word:.doc, .docx, or Lucid: .lk4, .lkc4, .data, .xml).
Auto match files to Entities option
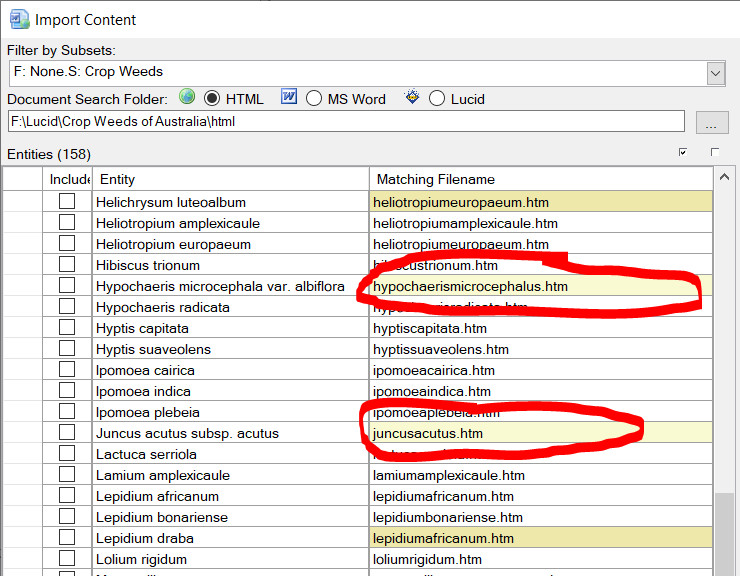
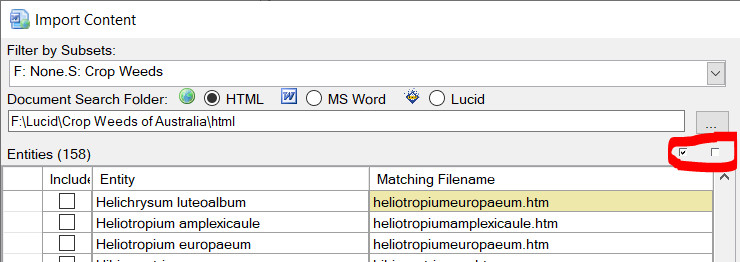
Documents found will then be compared against your Entity list. Matching documents (or Lucid Entities) will be automatically mapped as matching file names and listed in the ‘Matching Filename’ column. Closely matched documents will be highlighted in light yellow, while not so closely matched documents will be highlighted in a darker yellow. These non-matching documents should be examined to determine if they are the correct document to import for the given Entity. If the match document is incorrect, change the file name by typing in correct one in the ‘Matching Filename’ column, or use the browse option () to select the correct file. You can also preview the selected document by clicking on the preview icon. Example of matched documents to entities. Once you have mapped the Entities to the documents (or Lucid Entities) you wish to import against, select theses Entities by selecting the check boxes in the ‘Include’ column. You can select and un-select all Entities for inclusion or exclusion via the two check box options as shown in the screen capture below.
Select or un-select all options
Step 4.
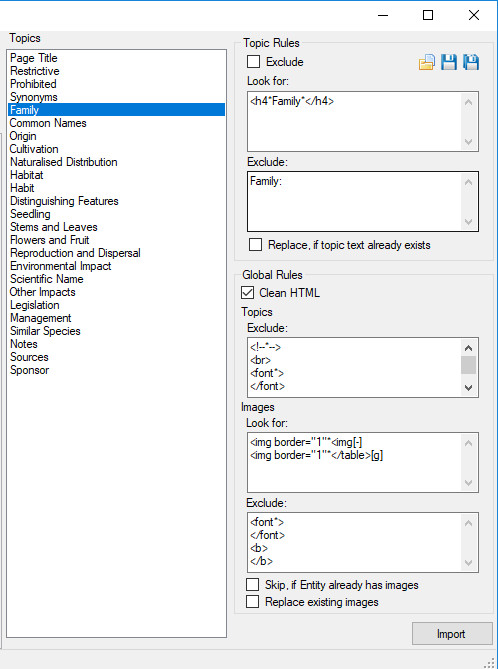
Within the middle of the import dialog is the list of the current projects Topics. Each of these Topics can be used to define a set of rules to capture content from the Entities matched document.
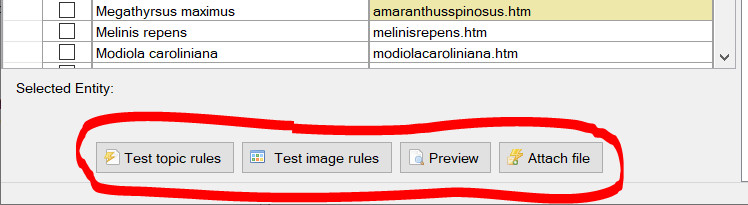
Select each Topic in turn to define the desired rules. Any Topic without rules will not have any content imported against it. After defining a rule or set of rules for a topic you can them against the selected entity documents. To test rules, select the topic containing the rules you wish to test, then select the entity matched document to run the rules against by clicking on the corresponding play button next to the matched filename column. If the rule(s) you have defined matches content within the document then the results of rule(s) will be displayed in a preview dialog.
Topics and import rules panel
Preview entity file, Play rule(s), and entity file browse buttons.
Preview entity file, Play rule(s), and entity file browse buttons.Preview rule results dialog
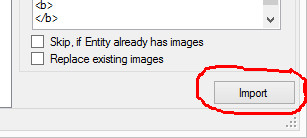
Once you have finished defining and testing your rule set click the Import button. During the import process Fact Sheet Fusion will show you the progress of the import via a green progress bar that will appear at the bottom of the dialog. Detailed information on defining import Rules are listed below.
Final stage – Select the Import button
Tip
If you are getting unexpected results from your rule set, check the Fact Sheet Fusion log file (via Help...About menu) as errors and warnings will be logged there.
Import Rules
Loading and Saving Rules
Defining rules for multiple Topics and images can take some time to get right, particularly when examining the document looking for consistent content and tags to match against. You can save your rule set to be used at a later date by selecting the save icon () (Ctrl + s shortcut key) or the Save As option located in the Topics Rules panel. This will save all rules for all Globally and Topics rules to a file with an extension called ‘.rules’. This can be loaded at a later time via the Open button () located to the left of the Save button. The loaded rules are matched against current Topic list. Any rule contained within a rules file that doesn’t match against an existing Topic will be ignored.
Note
If a topic has been renamed since the Rule set was saved you will either need to redefine the rules for that topic. Or you can edit the rule file and update the topic label in your preferred text editor.
Look For Rules
Look for rules are the instructions given to the import algorithm to find content within the Entities matched document. Multiple Look for rules can be defined, though each rule must be defined on its own line. Defining multiple Look for rules can be very handy when you want to capture content that maybe inconsistent between documents. For example, across many documents information may use consistent headings but differ slightly due to pluralisation. As an example some documents may contain a heading “Family:”, while others contain “Families:”.
Fragment content example: <h4>Family: Proteaceae</h4>
A second fragment example showing a different identifier of interest, targeted for the same Topic: <h4>Families: Myrtaceae, Mimosaceae and Rutaceae</h4>
Look for rules can be defined in a number of ways:
Note
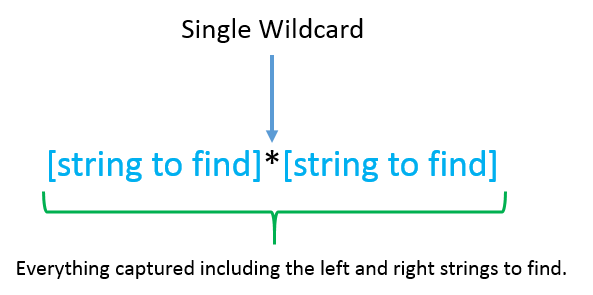
The import algorithm uses an asterisk (*) as a wildcard character. A wildcard character is used to represent one or more characters when searching. The wildcard character is a reserved character when defining search rules.
Using the simple examples above dealing with capturing the family name(s), the following two rules would be defined:
<h4*Family:*</h4> <h4*Families:*</h4>
Tip
The left string to find only defines part of the heading four tag. This is done because HTML tags may contain additional style definitions. E.g. <h4 style="...">. This way we ensure to capture any kind of heading four tag (plain or styled).
Only heading four tags would be returned that contained either ‘Family:’ or ‘Families:’. However since we already have a Topic in this instance is called ‘Family’ we don’t need to retain the ‘Family:’ or ‘Families:’ component of the returned match. This where we would use the exclusion rules to remove this text. Details of the exclusion rules are outlined further below in the Exclusion Rules section.
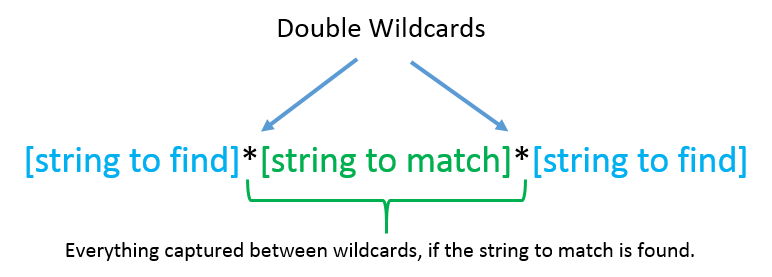
Using a single wild card option will return everything matched between the strings to find, but also include the strings to find in the returned matched text. For example, if we wanted to capture HTML tables and their content, we would need to search for the beginning and end table tags, but also retain them, so as not to break the HTML formatting.
E.g.
<table*</table>
Tip
Note the left string to find only defines part of the start of the table tag. This is done because HTML tags can contain additional definitions such as <table border="1" ...>. This way we ensure to capture all beginning table tags no matter how they are defined.
Additional Rule Options
When using the single wildcard search option it is not always desirable to keep the string to find. To remove it from the returned match use the following token ‘[-]’. To remove the left string to find you must define it to the left, while to remove the right string to find add it to the right. Adding the remove token to both the left and right strings to find is similar to the double wildcard, but without the additional ability to match on inner content.
As an example, if we were wanting to match on individual images within a block of images the only reliable next tag to search on may be the next image. E.g.
To capture these image tags we could do the do the following:
<img*<img[-]
In this example everything from the beginning of an image tag up until the next partial image tag (i.e. ‘<img’ ) would be captured. Though the ‘<img’ part of the right hand string to find would be discarded in the matched results.
Note
The above example would also need an additional rule to capture the last image as it would not have another beginning image tag for it to be matched on. See Greedy find option below.
The Greedy find option can be defined on to the end of any Look for rule and can be used in conjunction with the string removal rule. Consider the following example HTML content:
If we wanted to capture the last image within this div block we don’t necessarily have anything unique to match on. We can’t define the last image tag (<img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″>) as the left string to find since the file name and size will change from file to file. We could use the start of an image tag (<img). E.g.
<img*</div>
However this would return from the first image tag found to the end Div tag. E.g.
We also don’t need the end Div tag (</div>) as this would add a “broken” HTML tag to our matched content. To strip this from the matched results we just need to add the removal token. E.g.
Exclude rules use the exact same rule types as the Look For rules, however the Exclude rules only work on the matched results of the Look for rules. Unlike Look For rules Exclude rules can consist of rules that contain no wildcard characters. When no wildcard character is defined the entire string block is searched for and if found removed from the matched results. Exclude rules allow you to remove undesired content such as words, or HTML tags. Each Exclude rule must be defined on separate lines.
Some example Exclude rules:
Comment below here Remove the string ‘Comment below here’
<!–*–> Removes all HTML comments
<br> Remove all breaking returns
<font*> Removes all start font tags
</font> Removes all end font tags
<b*> Remove all bold tags
</b> Remove all bold end tags
<img*> Remove all images
<div*> remove all beginning Div tags
</div> Removes all end Div tags
Tip
If removing specific tags ensure you remove both the start and end tag.
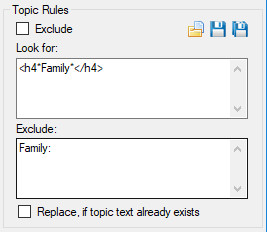
Topic Rules
Example Topic rules.
Exclude check box option will exclude this Topics rules from the import process. This is useful, for example, if you have saved a set of rules for processing multiple folders worth of content but don’t wish this Topic rule to be processed for one or more instances. Look for rules defined for the selected Topic. Exclude rules for the matched content of the Look for rules. Replace, if topic already exists check box will replace any topic text that may exist for that entity topic combination, if matching results are returned. If not checked and text already exists for the Entity Topic combination then no matched text will be saved.
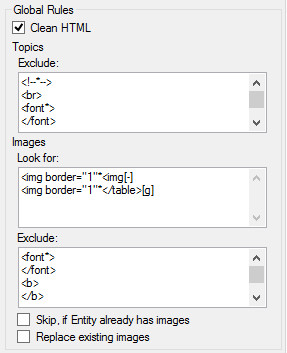
Global Rules
Example global rules.
Global rules are applied either for every topic or for matching images.
Clean HTML check box option will clean and remove any MS Word generated HTML formatting contained with the matched results of a rule. Topics Exclude rules. Any topic exclude rules defined here will be applied to every Topic result match after any specific Topic exclude rules have been processed. These global Topic Exclude rules save you from having to defined the same set of rules for every topic where you may want to remove common elements.
Images
The Fact Sheet Fusion import algorithm can also capture images and their captions, saving them to your database media store and automatically attaching them to the Entity being imported against.
Note
Detection and retrieval of embedded images within MS Word documents is not currently supported.
Look for rules – The Image Look for rules are the same rule types as defined in the Import Rules outlined above. However in many instances images also have a corresponding caption. When matching on image tags any remaining content captured outside of the image tag is treated as the caption block. Consider the following example HTML that contains a table with images and their captions on the row below:
<table> <tbody> <tr> <td><img src=”../../pict.jpg” width=”500″ height=”600″></td> <tr> <td><p>Example of the habit.</p></td> </tr> <tr> <td><img src=”../../plant1.jpg” width=”450 height=”300″></td> </tr> <tr> <td><p>Example of the tree in flower.</p></td> </tr> <tr> <td><img src=”../seed3.jpg” width=”250″ height=”300″></td> <tr> <td><p>Mature seed pod.</p></td> </tr> <td><img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″></td> <tr> <td><p>Bipinnate leaves</p></td> </tr> </tbody> </table>
We could use the following Image Look for rules:
<img*<img[-] <img*</table>[g]
The first rule will return each image along with all other content, except for the last image as there is no additional image tag to match on. The second rule uses the Greedy matching option to find the closest image tag to the end table tag to pick up the last image.
If we were to just define these two rules to find the desired images then we would be left with lots of broken inner table tags such as row tags and column tags. e.g.
First match:
<img src=”../../pict.jpg” width=”500″ height=”600″></td> <tr> <td><p>Example of the habit.</p></td> </tr> <tr> <td>
Second match:
<img src=”../../plant1.jpg” width=”450 height=”300″></td> </tr> <tr> <td><p>Example of the tree in flower.</p></td> </tr> <tr> <td>
Given these matches the import algorithm will take each of the image tags and find the corresponding image file and caption text, copy it and register it to the media store, then attach it as an Entity image.
Skip, if already Entity already has images option will not attach or store any matched images from the import if the Entity already has images associated with it.
Replace existing images option, if selected, will overwrite images that already exist in the database media store.
The HTML Editor is ‘text’ editor for the entering topic text and caption text within your project.
Full Toolbar
HTML Editor toolbar
Mini Toolbar
HTML Editor mini toolbar
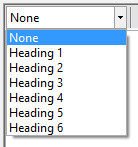
Heading Selector
HTML Editor Heading selector dropdown options
The heading selector allows you to select between several standard heading sizes. The heading size is applied to the currently selected line. A heading size can be removed by selecting the ‘None’ option. The heading size and style in the editor are only indications of the heading style. The selected fact sheet template will define the actual size and font type.
Cut
Any highlighted text will be cut from the editor to the clipboard.
Copy
Any highlighted text will be copied to the clipboard.
Paste
If the clipboard is not empty then the contents of the clip board will be pasted at the position of the cursor.
Tip
Use Ctrl + Shift + v keyboard combination to paste formatted content as plain text. E.g. MS Word or HTML clipboard content.
Undo
Will undo the last action performed. If the Undo button holds a history of steps performed within the editor, you can undo actions performed, such as delete, paste and typing, until the history is exhausted.
Redo
The redo action will redo any step that may have been undone by the Undo action.
Bold
Increases the importance of any selected text or makes any new text important from where the cursor is located. To remove bold text, highlight the desired portion and select bold again.
Underline
Underlines any text selected; or makes any new text underlined from where the cursor is located. To remove underline from text, highlight the desired portion and select underline again.
Italics
Emphasizes any selected text; or makes any new text italicized from where the cursor is located. To remove italics from the text, highlight the desired portion and select italic again.
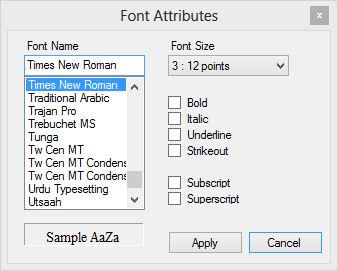
Edit Font
Font dialog
The edit font dialog will allow you to change the underlying font settings. However it is recommended that this facility is used only where absolutely necessary. Defining font settings within the HTML content will override the export template. Therefore it would be possible to cause a mis-match of font types within the exported fact sheet.
Normal (Remove font styles)
The Normal option removes any applied font styling from the selected text.
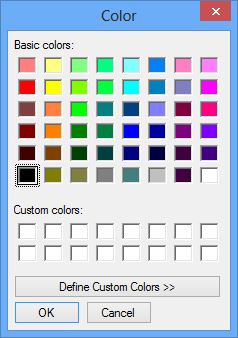
Edit Font Color
Font color dialog
The font color dialog will allow you to change the font color of the selected text. However any font styling, including color, will override the export template.
Increase the Font Size
This will increase the selected text font size incrementally each time it is selected. You can remove font sizing via the Normal option or reduce the font size using the Decrease font size option.
Decrease the Font Size
This will decrease the selected text font size incrementally each time it is selected. You can remove font sizing via the Normal option or increase the font size using the Increase font size option.
Left Justify
Positions selected text to the left of the text edit area.
Center
Positions text center in the text edit area.
Right Justify
Positions text to the right of the text edit area.
Indent
Moves the text a fixed amount to the right equivalent of one tab.
Outdent
Moves the text a fixed amount to the left equivalent of one tab.
Insert Ordered List
This option starts a numbered list. Each new line within the list is automatically assigned the next sequential number. The Indent and Outdent options can be used within the ordered list to create sub lists with their own sequential values.
Insert Unordered List
This option starts an unordered (bullet) list. Each new line within the list is automatically assigned a bullet icon. The Indent and Outdent options can be used within the ordered list to create sub lists with their bullet style. The style applied to each level within the list is determined by the web browser and the font used. This styling can be, easily overridden by the export template.
Insert Line
This option inserts a horizontal line at the position of the cursor.
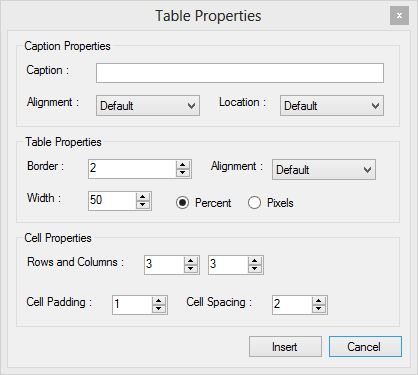
Insert Table
Table Properties dialog
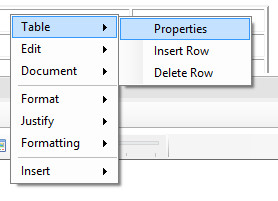
This dialog allows you to define the properties of a table to be inserted into the text edit area. Once the table has been created it can be easily modified by right clicking within the table area and selecting the table edit options.
Table pop-up context menu
Insert Image
This option has been disabled in this edition and may be added in a future release. If you wish to associate an image with a topic you can do so via the Topic Image tab or an image can be associated with the entity. The selected export template will then determine the layout and positioning of the image. Alternatively if you do wish to embed an image from an Internet location you can use the editing pop-up context menu to insert an image. If an image is embedded this way, the browser loading the exported page will need Internet access to display the image.
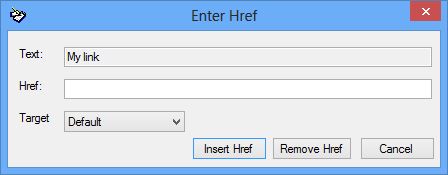
Insert Link
HTML Link edit dialog
This options allows you to create a link on highlighted text. If you are creating a link you can set the target (i.e. New window or the same window). The Href (hyperlink) should be a fully qualified URL (e.g. https://www.lucidcentral.org)
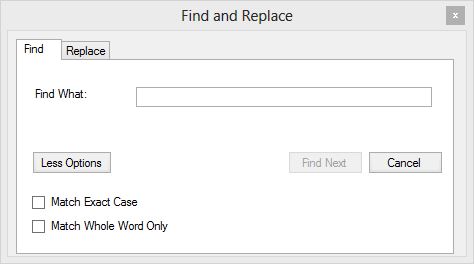
Find/Replace
Find dialog
The find dialog will search for given text within the current editor’s text area.
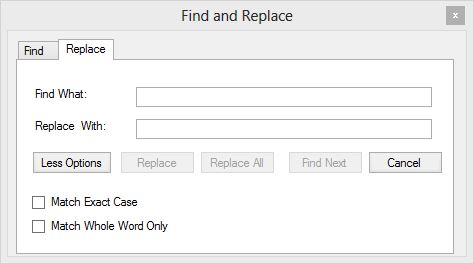
Replace dialog
The replace option allows you to perform a find and replace within the current text area.
Print
This option allows you to print the current text area content. It will open a print dialog allowing you to select your preferred printer and page options.
Clean HTML
Often when Microsoft Word content (or content of other Office applications) is pasted into the HTML editor, it is pasted with Microsoft Office HTML formatting, which will override the exported fact sheet template styles. The Clean HTML function is designed to remove most Microsoft Word HTML formatting, leaving the equivalent styling where possible, but without the use of embedded styles. This will leave the formatted content looking similar to “plain text”, but will generally look much better in the exported format once the template has been applied.
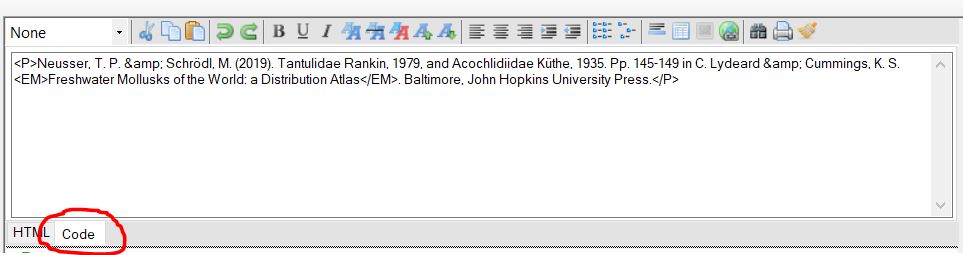
The Code tab within the HTML editor allows you access to the underlying HTML markup of the document. If you are comfortable with HTML you can edit the HTML markup directly. Switching back to the HTML tab will update the document with any changes that have been made. It is very important to maintain well formed HTML code within the HTML editor. That is, each HTML tag must have a start and end tag (other than breaking return tags (<br>) and horizontal lines (<hr>)).
If errors are made in the simple mark up, the editor will try and correct for this, i.e. append missing end tags, although in more complex tags, such as tables etc, this may not work. If “broken” HTML tagging is left within the editor this may affect the exported fact sheet with either an error when exporting or unexpected layout and formatting.