Importing Content
Step 1.
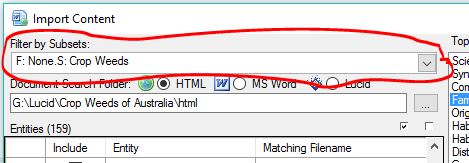
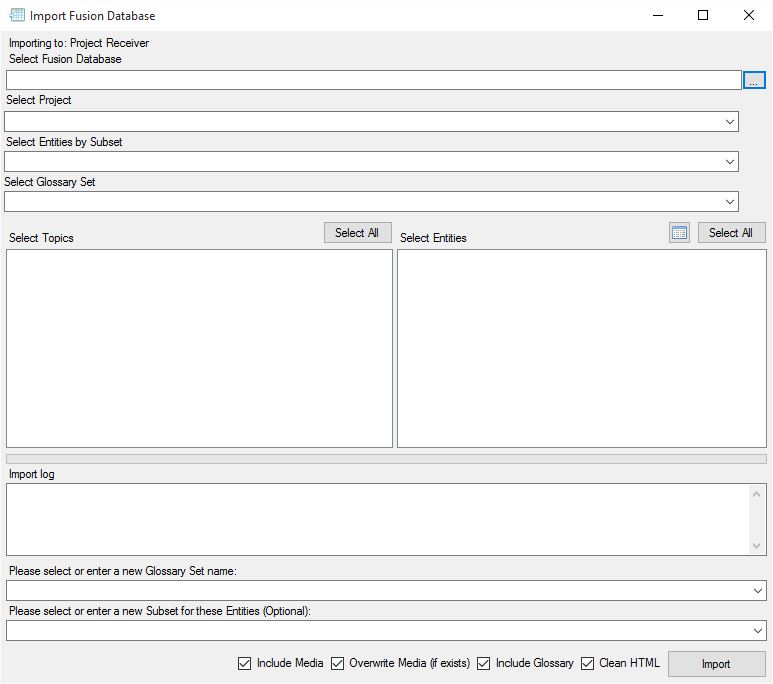
The first step in undertaking an import is to define the Entities you wish to import content for. These entities must already exist within your project. New Entities cannot be added via the Import dialog. Filtering of Entities can be done via the Filter by Subsets option located top left of the Import dialog. Entities can also be easily excluded from the import process by simply not selecting them to be included in the import process via the check box in the Include column. More information on this is detailed further below in Step 3.
Step 2.
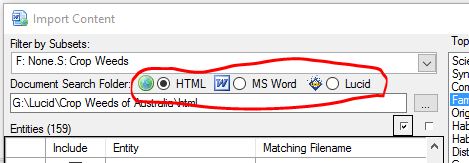
Select the document format are trying to importing from. I.e. HTML, MS Word or a supported Lucid key or data file.
Step 3.
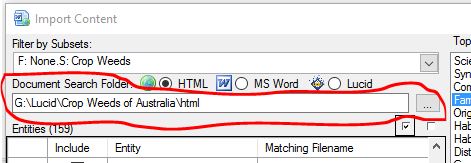
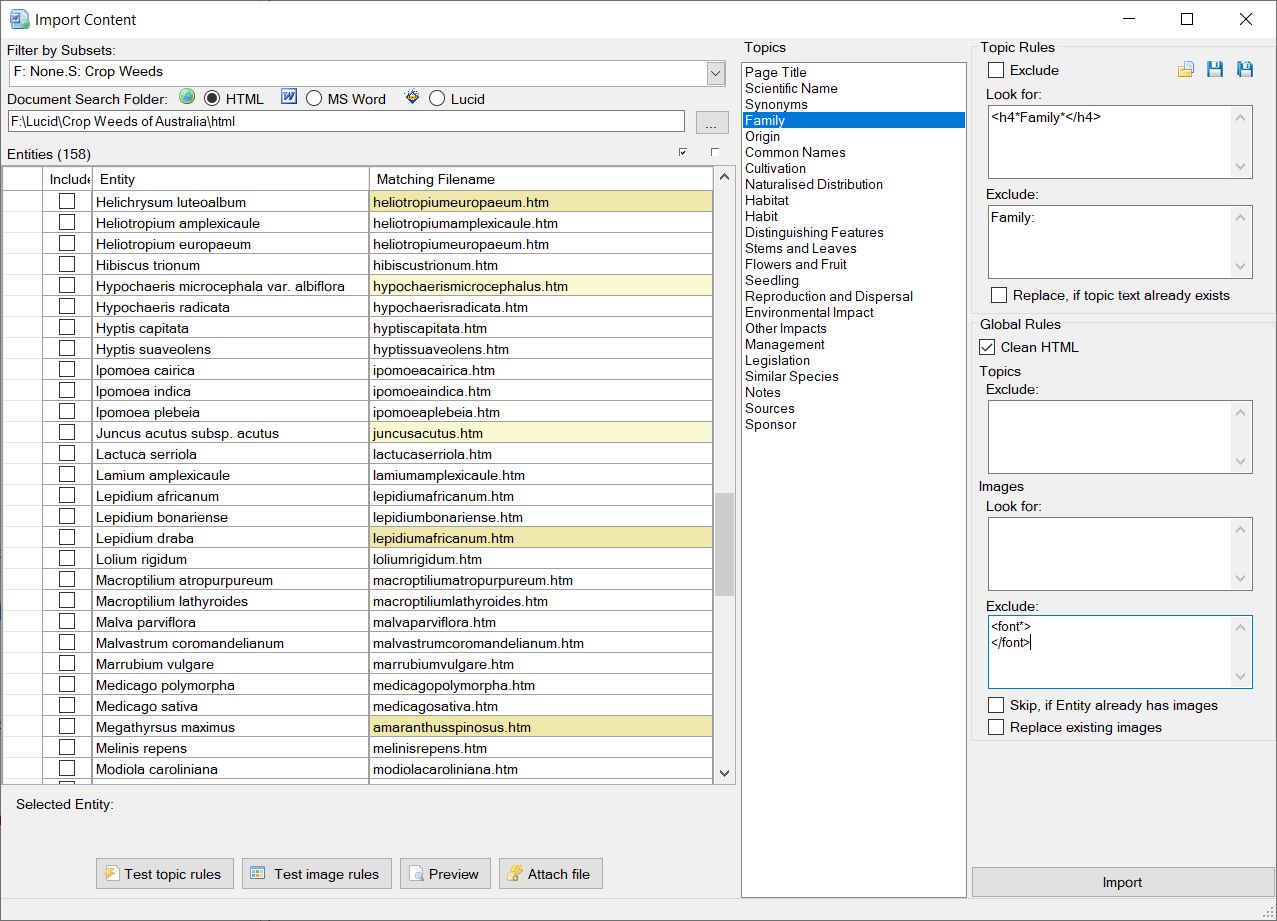
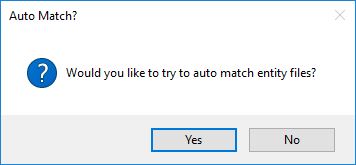
Use the document folder browse button to select the folder where the HTML, MS Word documents or Lucid key or data files are located. Once a valid folder or Lucid key file has been defined, the content importer will as if you wish to auto match the entities by scanning the folder or key for matching document types (HTML: .htm, .html or MS Word:.doc, .docx, or Lucid: .lk4, .lkc4, .data, .xml).
Documents found will then be compared against your Entity list. Matching documents (or Lucid Entities) will be automatically mapped as matching file names and listed in the ‘Matching Filename’ column. Closely matched documents will be highlighted in light yellow, while not so closely matched documents will be highlighted in a darker yellow. These non-matching documents should be examined to determine if they are the correct document to import for the given Entity. If the match document is incorrect, change the file name by typing in correct one in the ‘Matching Filename’ column, or use the browse option (![]() ) to select the correct file. You can also preview the selected document by clicking on the preview icon.
) to select the correct file. You can also preview the selected document by clicking on the preview icon.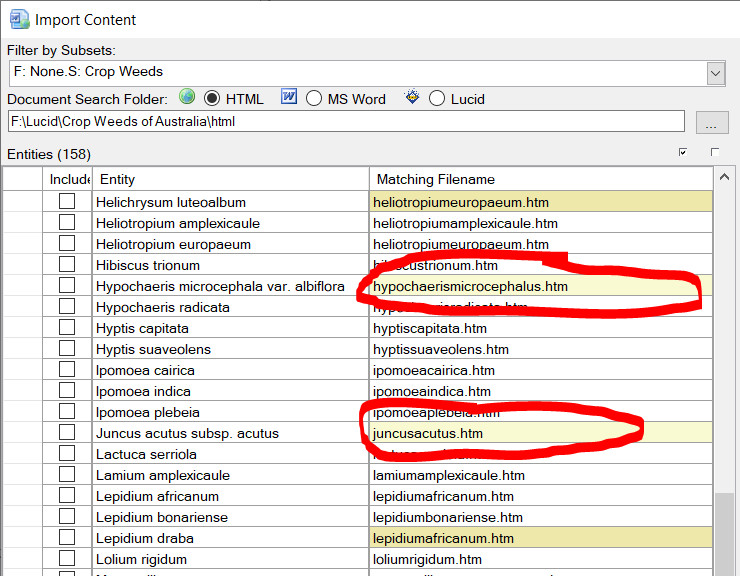
Example of matched documents to entities.
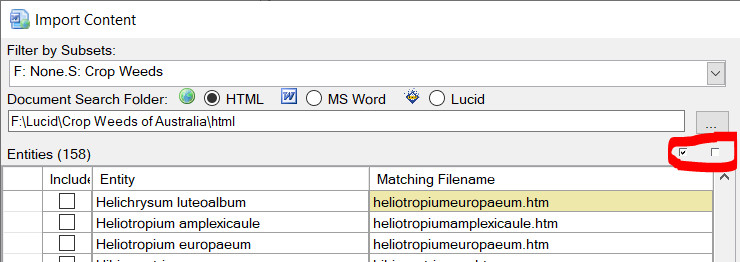
Once you have mapped the Entities to the documents (or Lucid Entities) you wish to import against, select theses Entities by selecting the check boxes in the ‘Include’ column. You can select and un-select all Entities for inclusion or exclusion via the two check box options as shown in the screen capture below.
Step 4.
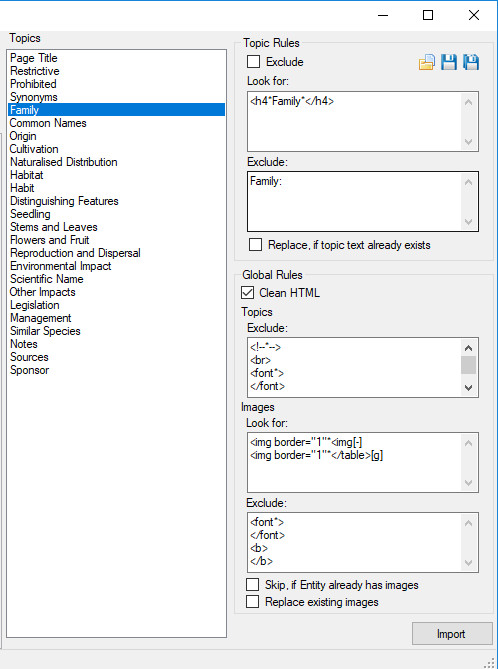
Within the middle of the import dialog is the list of the current projects Topics. Each of these Topics can be used to define a set of rules to capture content from the Entities matched document.
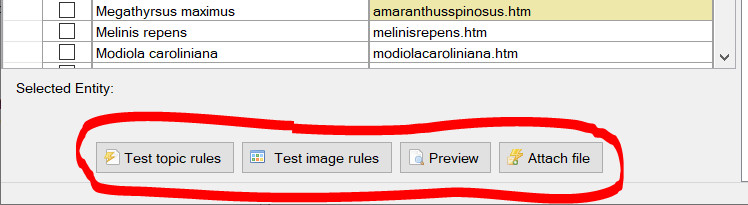
Select each Topic in turn to define the desired rules. Any Topic without rules will not have any content imported against it. After defining a rule or set of rules for a topic you can them against the selected entity documents. To test rules, select the topic containing the rules you wish to test, then select the entity matched document to run the rules against by clicking on the corresponding play button next to the matched filename column. If the rule(s) you have defined matches content within the document then the results of rule(s) will be displayed in a preview dialog.
Preview entity file, Play rule(s), and entity file browse buttons.

Once you have finished defining and testing your rule set click the Import button. During the import process Fact Sheet Fusion will show you the progress of the import via a green progress bar that will appear at the bottom of the dialog. Detailed information on defining import Rules are listed below.
Import Rules
Loading and Saving Rules
Defining rules for multiple Topics and images can take some time to get right, particularly when examining the document looking for consistent content and tags to match against. You can save your rule set to be used at a later date by selecting the save icon (![]() ) (Ctrl + s shortcut key) or the Save As option located in the Topics Rules panel. This will save all rules for all Globally and Topics rules to a file with an extension called ‘.rules’. This can be loaded at a later time via the Open button (
) (Ctrl + s shortcut key) or the Save As option located in the Topics Rules panel. This will save all rules for all Globally and Topics rules to a file with an extension called ‘.rules’. This can be loaded at a later time via the Open button (![]() ) located to the left of the Save button. The loaded rules are matched against current Topic list. Any rule contained within a rules file that doesn’t match against an existing Topic will be ignored.
) located to the left of the Save button. The loaded rules are matched against current Topic list. Any rule contained within a rules file that doesn’t match against an existing Topic will be ignored.
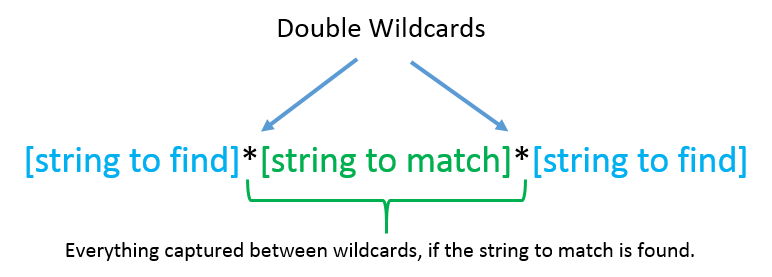
Only heading four tags would be returned that contained either ‘Family:’ or ‘Families:’. However since we already have a Topic in this instance is called ‘Family’ we don’t need to retain the ‘Family:’ or ‘Families:’ component of the returned match. This where we would use the exclusion rules to remove this text. Details of the exclusion rules are outlined further below in the Exclusion Rules section.
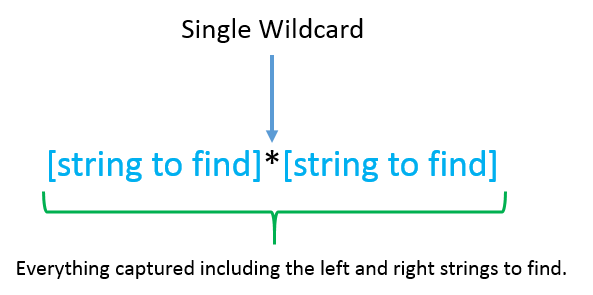
Using a single wild card option will return everything matched between the strings to find, but also include the strings to find in the returned matched text. For example, if we wanted to capture HTML tables and their content, we would need to search for the beginning and end table tags, but also retain them, so as not to break the HTML formatting.
E.g.
<table*</table>
Additional Rule Options

When using the single wildcard search option it is not always desirable to keep the string to find. To remove it from the returned match use the following token ‘[-]’. To remove the left string to find you must define it to the left, while to remove the right string to find add it to the right. Adding the remove token to both the left and right strings to find is similar to the double wildcard, but without the additional ability to match on inner content.
As an example, if we were wanting to match on individual images within a block of images the only reliable next tag to search on may be the next image. E.g.
<div><img src=”../../pict.jpg” width=”500″ height=”600″ /><img src=”../../plant1.jpg” width=”450 height=” /><img src=”../seed3.jpg” width=”250″ height=”300″ />
<img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″ /></div>
To capture these image tags we could do the do the following:
<img*<img[-]
In this example everything from the beginning of an image tag up until the next partial image tag (i.e. ‘<img’ ) would be captured. Though the ‘<img’ part of the right hand string to find would be discarded in the matched results.

The Greedy find option can be defined on to the end of any Look for rule and can be used in conjunction with the string removal rule. Consider the following example HTML content:
<div>
<img src=”../../pict.jpg” width=”500″ height=”600″><img src=”../../plant1.jpg” width=”450 height=”300″><img src=”../seed3.jpg” width=”250″ height=”300″>
<img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″>
</div>
If we wanted to capture the last image within this div block we don’t necessarily have anything unique to match on. We can’t define the last image tag (<img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″>) as the left string to find since the file name and size will change from file to file. We could use the start of an image tag (<img). E.g.
<img*</div>
However this would return from the first image tag found to the end Div tag. E.g.
<img src=”../../pict.jpg” width=”500″ height=”600″><img src=”../../plant1.jpg” width=”450 height=”300″><img src=”../seed3.jpg” width=”250″ height=”300″>
<img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″>
</div>
Using the Greedy option tells the matching algorithm to keep matching until the last instance of the match is found. E.g.
<img*</div>[g]
Would return:
<img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″>
</div>
We also don’t need the end Div tag (</div>) as this would add a “broken” HTML tag to our matched content. To strip this from the matched results we just need to add the removal token. E.g.
<img*</div>[g][-]
This would return:
<img src=”../../leaf223.jpg” width=”100″ height=”300″ border=”1″>
Exclude Rules
Exclude rules use the exact same rule types as the Look For rules, however the Exclude rules only work on the matched results of the Look for rules. Unlike Look For rules Exclude rules can consist of rules that contain no wildcard characters. When no wildcard character is defined the entire string block is searched for and if found removed from the matched results. Exclude rules allow you to remove undesired content such as words, or HTML tags. Each Exclude rule must be defined on separate lines.
Some example Exclude rules:
Comment below here
Remove the string ‘Comment below here’
<!–*–>
Removes all HTML comments
<br>
Remove all breaking returns
<font*>
Removes all start font tags
</font>
Removes all end font tags
<b*>
Remove all bold tags
</b>
Remove all bold end tags
<img*>
Remove all images
<div*>
remove all beginning Div tags
</div>
Removes all end Div tags
Topic Rules
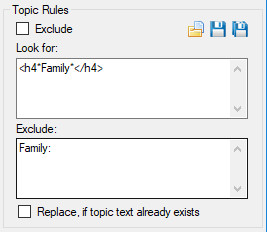
Exclude check box option will exclude this Topics rules from the import process. This is useful, for example, if you have saved a set of rules for processing multiple folders worth of content but don’t wish this Topic rule to be processed for one or more instances.
Look for rules defined for the selected Topic.
Exclude rules for the matched content of the Look for rules.
Replace, if topic already exists check box will replace any topic text that may exist for that entity topic combination, if matching results are returned. If not checked and text already exists for the Entity Topic combination then no matched text will be saved.
Global Rules
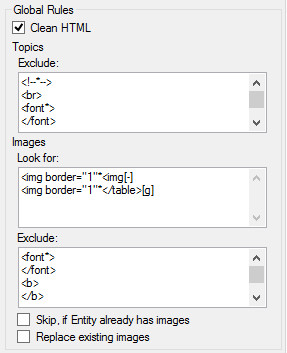
Global rules are applied either for every topic or for matching images.
Clean HTML check box option will clean and remove any MS Word generated HTML formatting contained with the matched results of a rule.
Topics Exclude rules. Any topic exclude rules defined here will be applied to every Topic result match after any specific Topic exclude rules have been processed. These global Topic Exclude rules save you from having to defined the same set of rules for every topic where you may want to remove common elements.
Images
The Fact Sheet Fusion import algorithm can also capture images and their captions, saving them to your database media store and automatically attaching them to the Entity being imported against.