Fact Sheet Fusion can now import data directly from an Excel spreadsheet. The Excel import module will import entities, topics and the entity topic text.
Entities and topics don’t first need to exist in the Entity and Topics lists prior to import. I.e., You can import into a completely empty FSF database or one with existing data.
If you have existing topics, you can map these to the Excel columns. If you map the same topic to more than one column the text data will be added together with each column text block wrapped in P tags.
Excel spreadsheet requirements:
- The first row must contain the topic heading’s.
- The first row/column can be empty (or contain a text value, but it will be ignored).
- The first column must contain the entities.
- The topic text is the intersect of the row/column. Only cells containing a value will be imported.
- If the spreadsheet contains calculated cells then the formula must be valid along with a recognised result of ‘String’, Integer or Boolean (True/False).
There is no undo after importing, so always back up your database prior to importing.
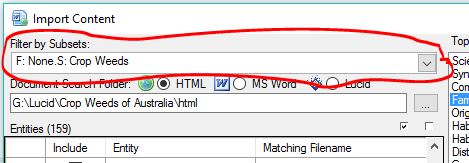
To access the Excel Import option you first must have created your Fusion database and a project. Once the project is open use the menu to open the Excel Import dialog as shown.
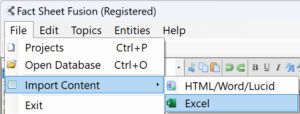
Below is a screen shot of the Excel Import dialog prior to loading an Excel spreadsheet.

Use the ‘Select Excel file’ to browse and select your Excel spreadsheet.
![]()
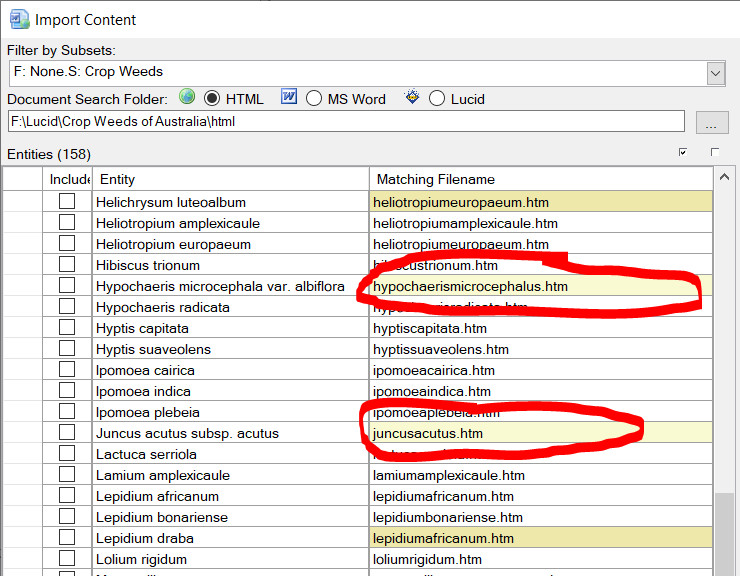
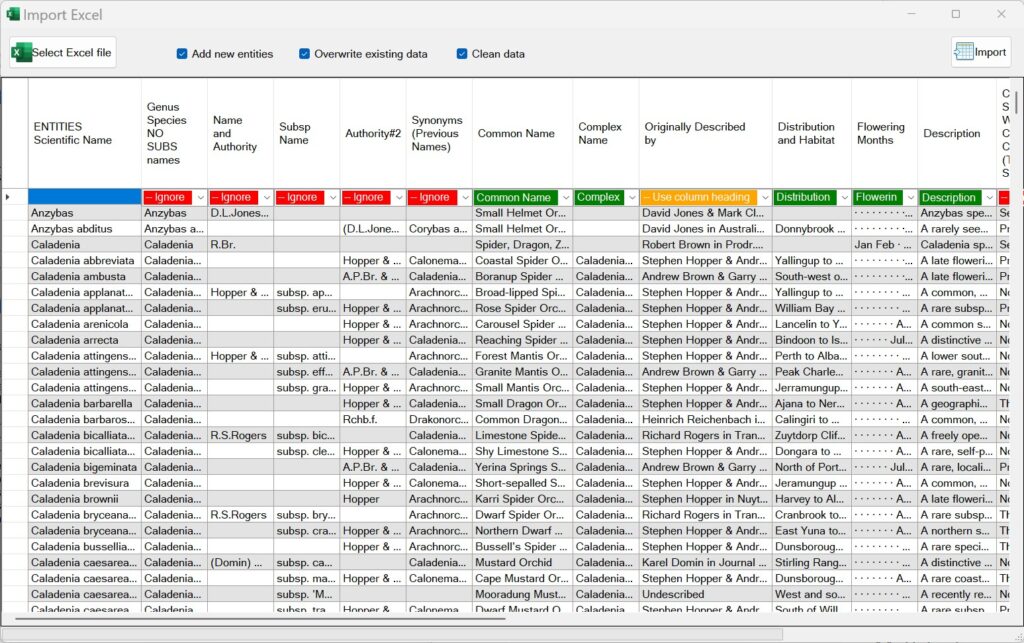
If your spreadsheet conforms to the required format you should see your topics listed in the first row, your entities in the first column along with the entity/topic text intersecting these.
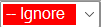
The second row will contain import dropdown options. The options available depend if your Fusion project already has topics. By default the import option is to ignore the column of data (the topic) (colored red).
If you select the dropdown, along with the ignore option, you will see:
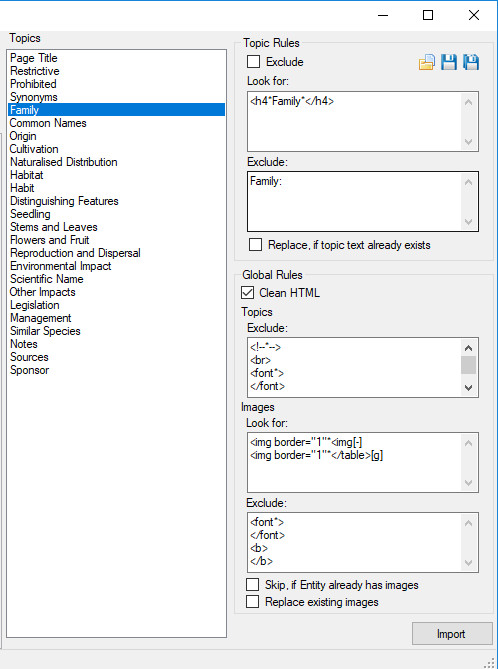
- An option to ‘Use column heading’ (colored orange). If selected the column heading (row 1) will be used to create a new Topic and the data for each of the entities (listed in the first column) imported into the project.

Excel import use column heading as a new topic. - If Topics already exist within the project they will be listed in the dropdown (colored green), if selected, the column data will be imported into the project for that Topic and corresponding Entities (found in column one). You can elect to map the same topic across multiple columns of the spreadsheet. In this scenario the data will be appended together with P tags for each of the Entities.

Excel import map column to an existing topic.
Import options
![]()
Add new entities
If selected, any new Entities that don’t already exist in the Fusion project will be created. Otherwise, only entities that do exist will have data imported from the spreadsheet.
Overwrite existing data
If enabled, any existing Topic text associated with the entity/topic will be overwritten. Otherwise, if topic text already exists in the Fusion project for the Entity/Topic combination then the topic text from the spreadsheet will be ignored.
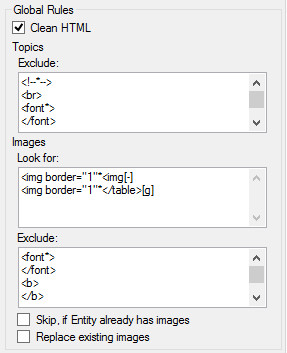
Clean data
The spreadsheet topic text may contain Html formatting or other undesirable formatting. If selected, Fusion will clean the Topic text of this undesirable formatting while still retaining basic formats such as bold and italics. This cleaning process is the same as the Topic clean option in the both the Topic editor and the Global clean option.
Importing data
Once you have elected the columns of data to import and the topics they will match or create click the Import button.
![]()
Progress of the import will be displayed within the bottom status bar of the dialog, along with a completion message once all the data has been imported. Close the dialog to return the the main Fusion project editing interface.
FAQs
Q. How can limit the entity rows for import?
A. Use excel to remove unwanted rows prior to import.
Related topics
Click here read about importing HTML, Word or Lucid key data.