General properties for the key are set using the Key properties tab at the left of the main panels.
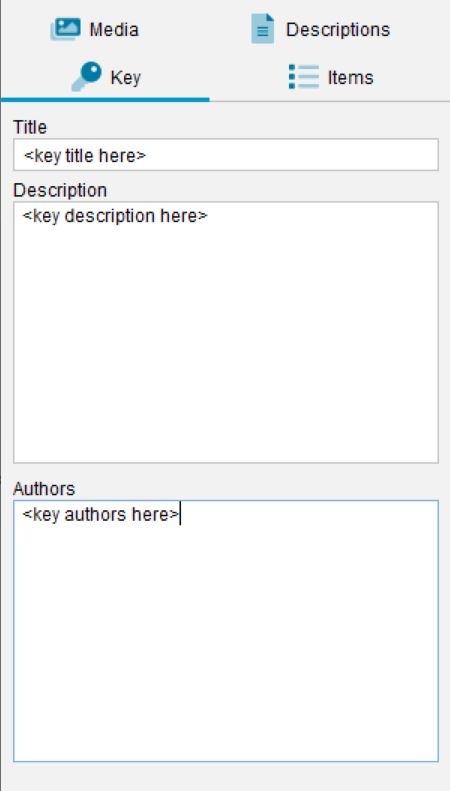
Lucid Builder Key Properties panel
Key Title
The Key Title should provide an appropriate, short, one-line name for the key, such as Key to Mangroves of Australia, Fly Families of the World or Common Diseases of Rice in South-east Asia. The key title is displayed as the header for the key window when the key is played in the Lucid Player.
Note that the title of the key is independent of the file name that is used to save the key. However, it will often be found useful to use the key title also for the file name, to help locate the key quickly on a hard drive or other storage.
Key Description
The Key Description provides a place to record any details about the key that may help you when you next open the key, or when you distribute your key to another party. Key Description may, for example, contain details such as the key’s purpose, target audience, limitations, version number and date etc. The information in Key Description is not published with a compiled key.
Key Authors
Key Authors provides a place to record authorship and authorship details (such as email addresses etc). The information in Key Authors is not published with a compiled key.
Tip
You can enter basic HTML tags within the title, description and author text areas. This information can be used as a part of the key deployment process, if you elect to have the Lucid Builder create a home page for the key.
If you would like an introduction to HTML basics take a look at w3schools.com.
Dependencies are logical relationships between Features such that a State of one Feature controls the presence (or absence) of another Feature in Features Available.
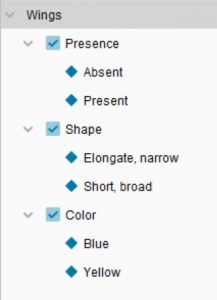
Consider, for example, the following Features:
Lucid Builder Features example
Wing colour and Wing shape only have meaning when wings are present – if wings are absent, they are logically inappropriate in the key.
Lucid provides two ways of accommodating logical dependencies of this kind. In the Lucid Builder, you may set a negative dependency such that, in the Player, if a user chooses the state Wings: absent, then the features Wing Colour and Wing Shape will be removed from Features Available. Alternatively, you may set a positive dependency such that Wing Colour and Wing Shape are initially hidden and only appear if a user chooses the state Wings: present.
Dependencies can help to keep the list of Features Available cleaner and less cluttered, and help make some Features, such as Best, work better.
Tip
If a Feature has been given both a Positive and Negative dependency, the negative dependency will be given preference.
How to set dependencies
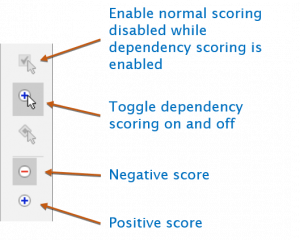
To set dependencies, click the Dependencies score button on the right hand score toolbar. In dependency scoring mode, two buttons will appear to enable the setting of positive and negative dependencies.
Lucid Builder Dependency Score options
You may set the dependent Features for a given controlling State, or the controlling states for a given dependent Feature.
To set dependent Features for a controlling State, first specify the ‘Controlling State’ by selecting the state in the Features tree then using the right-click context menu: the selected State will be highlighted, indicating that dependencies are currently being set for this State. Round dependency score boxes will appear alongside Features that may be controlled by this State.
To score a dependency, select the dependency type (positive or negative) and click the appropriate dependency score boxes.
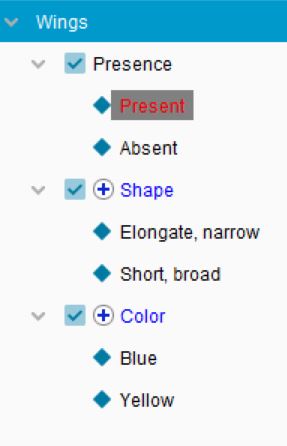
Lucid Builder Positive Dependency Scoring example
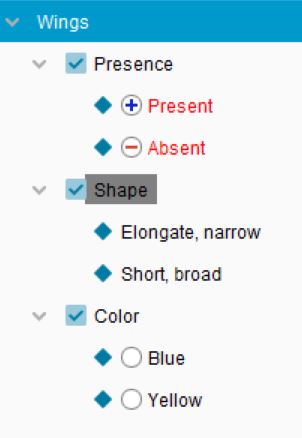
Setting positive dependencies for a State. With Wings: present selected, positive dependencies have been set for Wing colour and Wing Shape. If the user of the key chooses Wings: present, these Features will appear in Features Available.
Lucid Builder Negative Dependency Scoring example
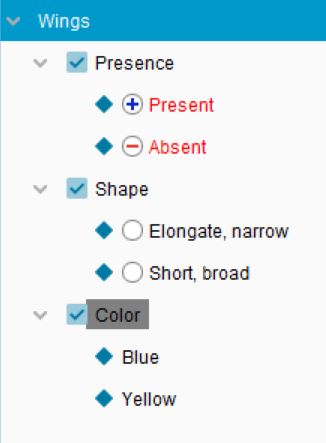
Setting negative dependencies for a State. With Wings: absent selected, negative dependencies have been set for Wing colour and Wing Shape. If the user of the key chooses Wings: absent, these Features will disappear from Features Available.
Lucid Builder Positive Dependency Scoring exampleLucid Builder Feature selection Dependency scoring example one
Setting a positive dependency for a Feature. With Wing shape selected, a positive dependency has been set on the controlling state Wings: present. If the user of the key chooses Wings: present,Wing Shape will appear in Features Available.
Lucid Builder Feature selection Dependency scoring example two
Setting a negative dependency for a Feature. With Wing shape selected, a negative dependency has been set on the controlling State Wings: absent. If the user of the key chooses Wings: absent,Wing Shape will disappear from Features Available.
To set controlling states for a dependent Feature, first select the Feature you wish to control by selecting it in the Features tree and using the right-click context menu: the selected feature will be highlighted, indicating that dependencies are currently being set for this feature. Round dependency score boxes will appear alongside States that may control this feature.
When to use positive and negative dependencies
The choice as to whether to set positive or negative dependencies will depend on the circumstances of the key and the likely key users.
In a key with all negative dependencies, at start-up (or when the key is restarted) all features will be displayed. Features that are logically inappropriate will be progressively removed from the key as the user proceeds. In the example used in the previous topic, a user with a specimen with blue wings would be able to address the Wing colour Feature at the beginning of the key, even before they have addressed the Wing presence Feature. This may be advantageous for your key. The disadvantage is that, at times, there may be many features at start-up that are not relevant to the specimen being identified.
By contrast, in a key with all positive dependencies, many Features will be hidden at start-up. You will effectively be constraining the choices your user may make: to be able to address the Feature Wing Colour they will need to first address the Feature Wing presence. The key will progressively unfold, becoming more applicable as the identification proceeds. This may be advantageous for your key. The disadvantage is that some Features will not be immediately available for use.
Note
It is possible to mix positive and negative dependencies in one key. Be aware, though, that dependencies may clash, or even contradict other dependencies. In all cases of conflict between dependencies, a negative dependency has priority over a positive dependency.
Positive dependencies, feature scopes and unfolding keys
Both positive dependencies and feature scopes may be used to create unfolding keys in which some features are hidden at start-up and are progressively added to Features Available as they become useful for the identification.
For more information on feature scopes, see the topic Not Scoped. For more on positive dependencies see the topic How to set dependencies above.
The difference between an unfolding key built using positive dependencies and one built using feature scopes lies in how the appearance of the hidden features is controlled. A hidden feature controlled using a positive dependency will be added into Features Available when its controlling state has been chosen, no matter what set of entities remains in Entities Remaining. By contrast, a hidden feature controlled using feature scopes will be added into Features Available whenever all entities in Entities Remaining are scored for the feature, no matter what set of states have been chosen from Features Available.
For example, consider an unfolding key to arthropods created using positive dependencies. Some features concerning wings are controlled by a positive dependency on the state Wings: present. These wing features will unfold into the key as soon as Wings: present is chosen, no matter which entities remain in Entities Remaining.
Consider the same key created using feature scopes. Some features concerning wings are scored only for the winged entities (that is, all wingless entities have been given the score Not Scoped for these features, while the winged entities have been given normal scores such as Absent, Common, Rare etc). These features will unfold into the key as soon as only winged entities remain in Entities Remaining, no matter which states were chosen to get there.
The choice of whether to use positive dependencies or feature scopes to create an unfolding key depends on personal preference and the likely way in which key users will approach an identification.
Report Dependencies
Reports on positive and negative dependencies contained within the key. Within large, complex keys with multiple dependencies set it is sometimes easier to view a report on dependencies, rather than selecting them individually, via the dependency scoring interface, to see what they may affect.
This option can be accessed via the ‘Keys…Scores…View Dependencies’ menu.
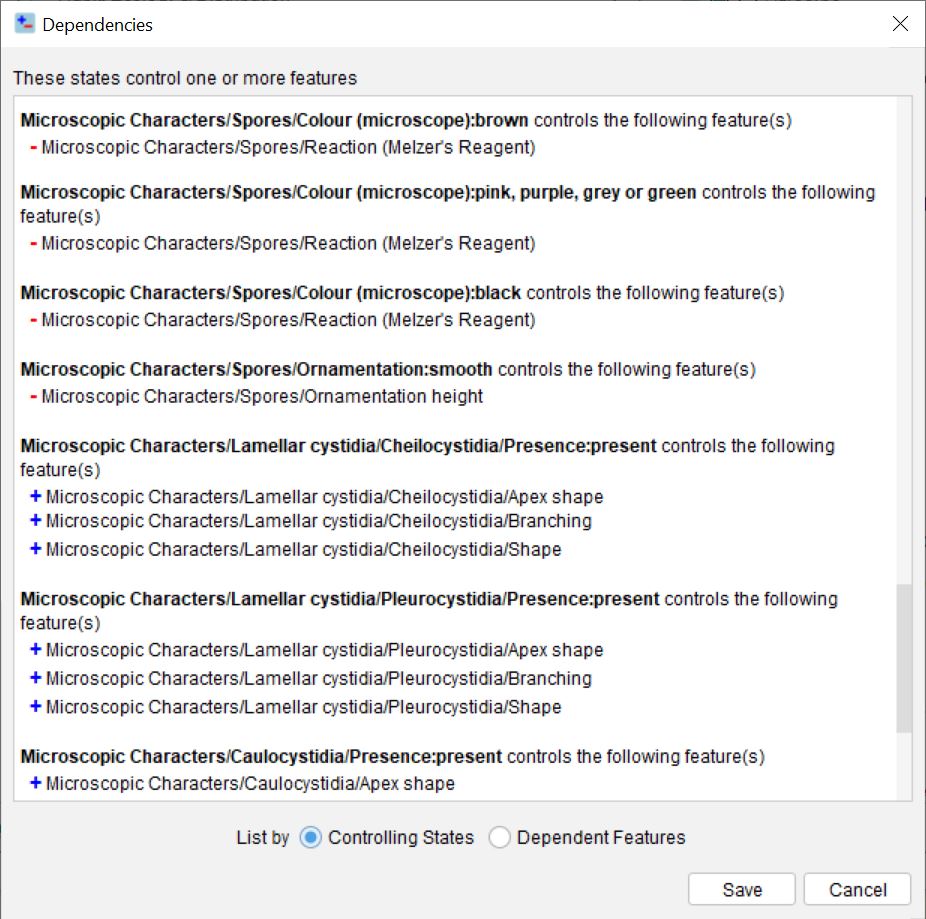
Lucid Builder Dependencies Report example
The Dependency Reporter reports positive and negative dependencies in two ways –
By the controlling State and;
By Feature.
By Controlling States
A controlling State is a Feature State that contains a Positive or Negative Dependency that will cause other Features to be added (positive) or removed (negative) upon its selection.
Within the report all controlling states are listed with the Features each controlling state will add or remove if the user selects that state.
By Feature
Lists all Features that have a positive or negative dependency set against it, along with the Features/State controlling that Feature.
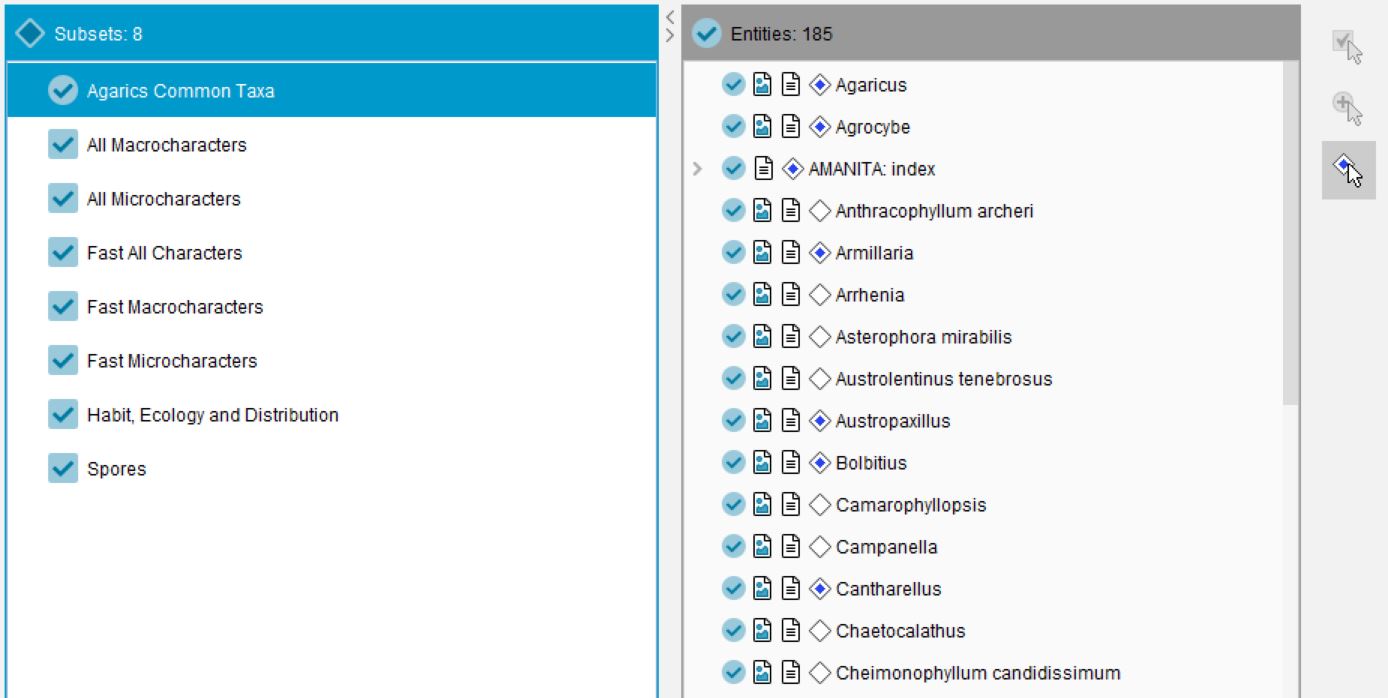
Subsets of items provide a way for users to organise and arrange the features and entities in the key.
A subset is a named collection of features or entities. For example, a key to fungi may have feature sets named Macroscopic Features, Microscopic Features and Chemical Features. A user of the key who wishes to use only macroscopic features (perhaps because the user does not have a microscope or access to chemical analysis facilities) will choose the Macroscopic Features subset, and only macroscopic features will be displayed in Features Available. Similarly, the key may have entity sets named Common Fungi and Rare Fungi. A user of the key may wish to use the Common Fungi subset to remove all rare fungi from the key.
Subsets can also be used in the deployment of the key to create a key that only contains those items found in the subsets selected. That is you can create sub keys from the selection of the feature and entity subsets. See the Key Deployment help topic for more information.
In Lucid Version 2, Subsets were called Sets, and many Lucid2 keys use sets to arrange features into morphological categories. For example, a key to plants may include the sets Leaves, Flowers, Fruits etc. In a Lucid v4 key another way of arranging Features and Entities is provided by the hierarchy of items in the Features and Entities trees. However, feature subsets are still needed in order to reduce the key to one or more subsets of features, especially when using the key in List View and when using Best.
How to create subsets
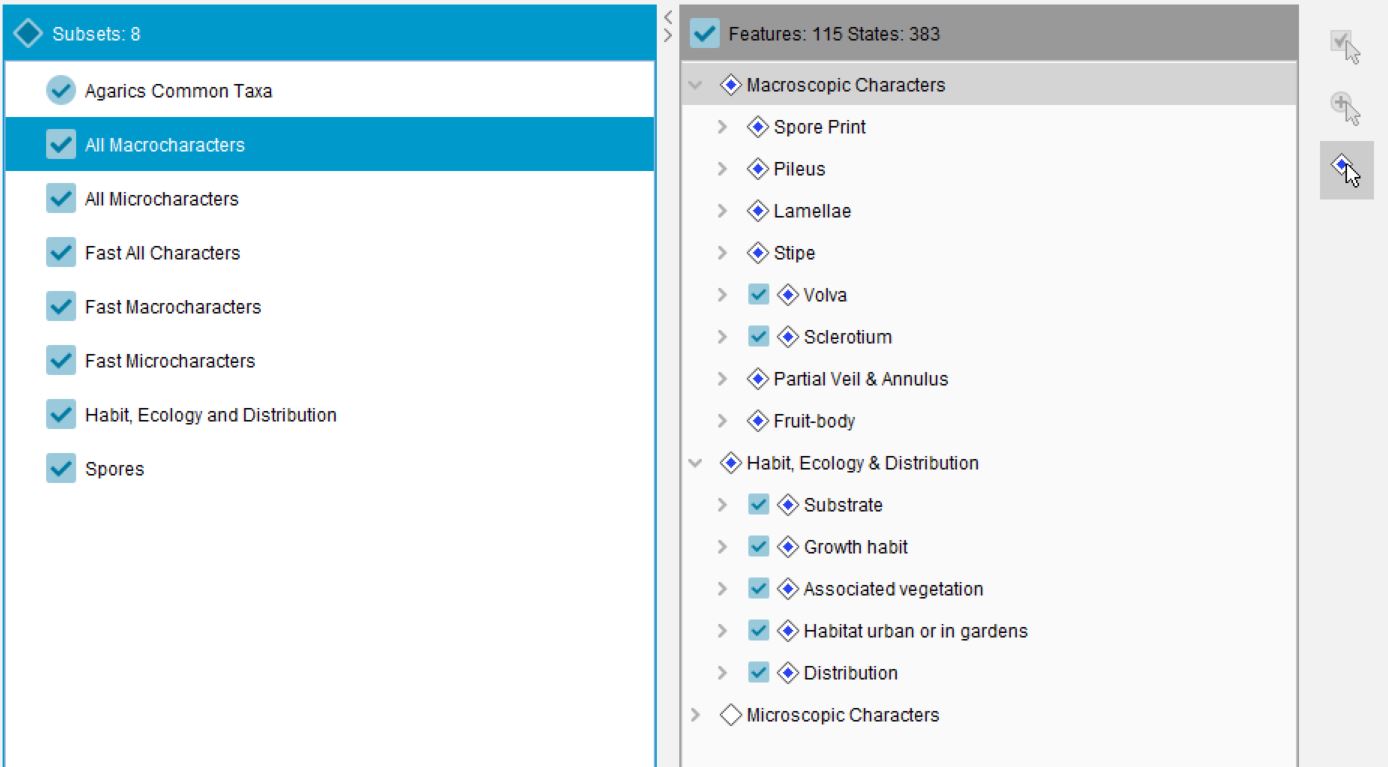
Subsets are created and managed using the Subsets panel. Once a subset has been created, items are assigned to the subset by “scoring” them for a given subset, equivalent to scoring features and items.
To open the Subsets panel, click the Subsets button on the toolbar.
Lucid Builder Feature Subset exampleLucid Builder Entities Subset example
To add a Subset right click within the Subsets panel and select either the Add…Feature subset or Entity subset from the context pop-up menu.
Add Subset context pop-up menu
How to score subsets
Score subsets by clicking the Score Subset button on the score toolbar, then selecting a subset in the Subsets panel. If the selected subset is a Features subset, round subset score boxes will appear against features in the Features panel; if the selected subset is an Entities subset, round subset score boxes will appear against entities in the Entities panel. Add an item to a subset by clicking on its score box.
Tip
When scoring subsets in feature or entity trees, holding down the Control key while clicking on a subset score box will cause all children of the scored item to be also included in the subset. If an item is included in the subset its parent (and other ancestors) must be included in the subset also.
Subsets can be added, deleted, moved, renamed and re-scored at any time.
Setting default subsets
Subsets can be set as default features and/or entities when the key is opened in the Lucid Player. To have a subset used by default select the Items tab and select the Default Subset check box.
Note
Subsets panel needs to be visible before the Default Subset check box is visible in the Items tab.
Once a key is partially scored, you may analyse the scoring using the Score Analyser. The Score Analyser provides two main types of analysis:
A Difference analysis is used to identify pairs or groups of Entities that a user of the key will have difficulty separating, because there are few differences in their scoring. Adding more Features that differ between such Entities would improve the key. While the Lucid Builder cannot tell you which Features to add, pointing out which Entities need more Features may help you improve the key.
A Polymorphism analysis identifies taxa that are more or less polymorphic in their scoring. A taxon is polymorphic when it is scored for two or more States of a Feature. Taxa that are highly polymorphic (I.e. frequently scored for two or more States per Feature) will be difficult to remove from Entities Remaining even when the particular set of States chosen does not occur in the Entity – that is, they may be falsely retained. Splitting highly polymorphic taxa into two or more less-polymorphic subtaxa will improve the efficiency of the key.
The Score Analyser is started by choosing the Score Analyser tab.
Lucid Builder Score Analyser tab
After analysis, choose Differences by Entity or Differences by group to perform a difference analysis, or Polymorphisms to produce a polymorphism analysis.
Difference Analysis
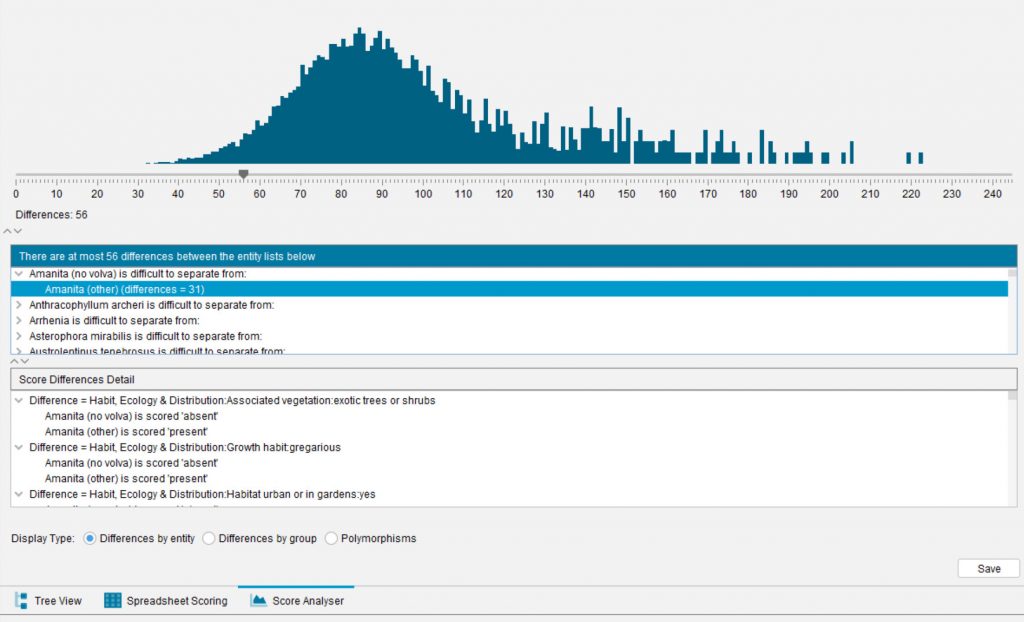
The Score Analyser displays a bar graph showing the number of differences between all pairs of Entities.
Lucid Builder Score Analyser example
On the left of the graph are pairs of Entities that differ by relatively few Features; on the right of the graph are pairs of Entities that differ by many Features.
The slider on the bar graph is used to find those pairs of Entities that differ by less than a nominated number of features. Move the slider to a position on the left tail of the graph, and the middle panel of the Score Analyser will display all pairs of Entities that differ by less than the nominated number of features. Selecting an entity in the middle panel will display the Features that differ.
If Differences by Entity is selected, the middle panel will list Entities in order of each Entity. If Differences by groups is selected, the lower panel will display Entities that form mutually difficult groups.
Use Save to File to save the results of the lowermost panels to a text file.
Polymorphism Analysis
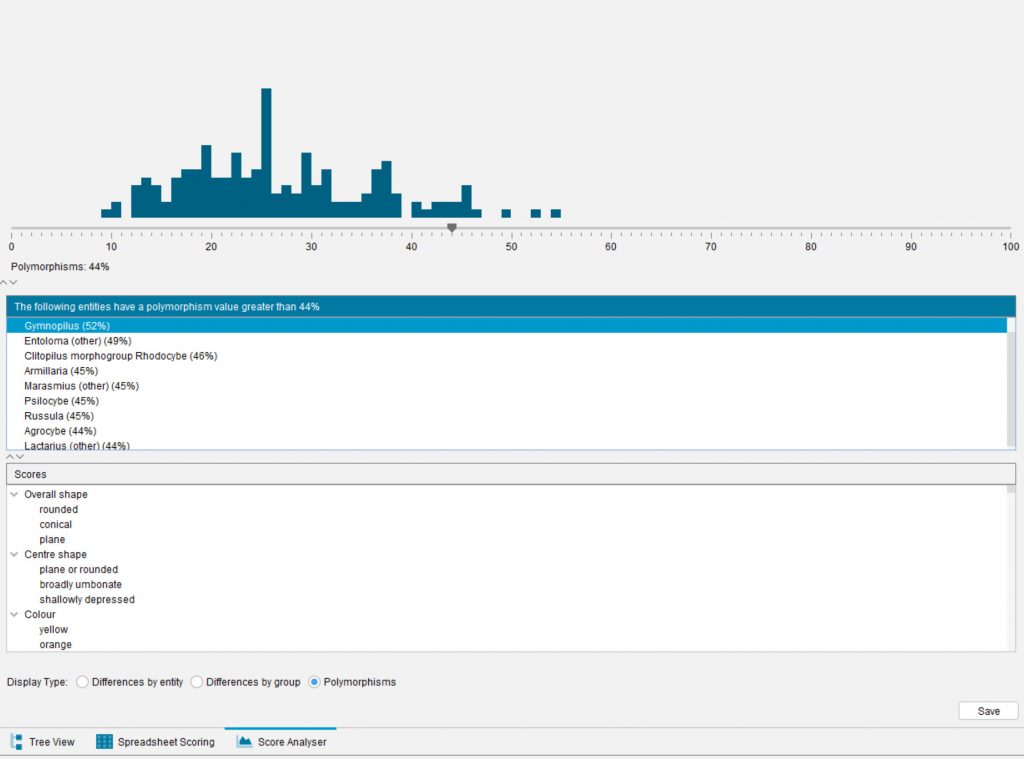
The Score Analyser displays a bar graph showing the distribution of polymorphisms for the Entities in the key. The polymorphism score of an Entity is a percentage of the total number of States scored non-absent for the Entity divided by the total number of States in the key.
Lucid Builder Score Analyser Polymorphisms example
The slider on the bar graph is used to find those entities that are highly polymorphic. Move the slider to a position on the right tail of the graph, and the middle panel of the Score Analyser will display all Entities with a polymorphism value greater than the nominated value. Selecting an Entity in the middle panel will display the features that are scored polymorphically, with their scored States.
Use Save button to save the results of the lowermost panels to a text file.
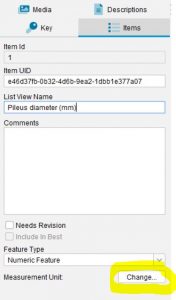
Lucid Builder Properties Panel Change Measurement Units
Numeric features that represent a measurement (such as Antenna length) should have a specified measurement unit (e.g. cm).
Measurement units are set using the Measurement Unit dialog. This is accessed by clicking on the Change… button on the Items panel.
To specify an SI measurement unit, select a base unit and (if appropriate) a default prefix from the drop-down boxes. For example, to specify a unit of centimetres (cm), choose m (metres) as the base unit and c (centi) as the default prefix.
The possible base units values are:
none
m (metre)
m2 (square metre)
m3 (cubic metre)
l (litre)
°C (degrees Celsius)
° (degrees planar)
other (user specified unit – string)
The possible unit prefixes are:
none
k (kilo)
h (hecto)
da (deca)
d (deci)
c (centi)
m (milli)
µ (micro)
To specify a non-SI unit (e.g. inches), type the name of the unit into the Base Unit box.
When scoring numeric features, the Numerics dialog box displays the default unit (a concatenation of the prefix and base unit). Clicking on the Units value will allow you to choose alternate units (based on the same base) from a dropdown box. For example, if the default measurement unit is cm, you may enter values for different taxa in cm, mm, dm etc. Lucid will automatically convert all measures to the default unit for storage.
Lucid Builder Numeric Feature Scoring example
Note
When using non-SI base units, alternate unit prefixes (e.g. milli-inch, kilo-inch etc) may be chosen in the Numeric Scores dialog. This should not be done, as non-SI units are not automatically converted to the default unit for storage.
No prefixes are available if the base unit chosen is °, °C or (none).
The Lucid Absent score is used to record that a state of a feature does not occur in an entity. This should be a definitive statement: if you are uncertain whether a state does or does not occur, it is safer to use the Uncertain score.
Absent is, in some ways, the most important score in Lucid. If an entity is scored as Absent for a state and a user of the Lucid Player chooses the state, the entity will be discarded from Entities Remaining into Entities Discarded, and hence will be removed from contention for the identification. A false Absent is a more serious error in a key than a false Present, since it will cause an entity to be falsely removed from Entities Remaining, and hence may preclude a correct identification.
Absent is the default score given to all entities for all states, until another score is given.
For numeric features, Absent is the default score if no numeric record has been entered for the entity. See the topic Scoring numeric features for more details.
Common
Common is the normal score given in Lucid when a state occurs in an entity. For example, if a species of plant always or usually has blue flowers, the state blue of the feature Flower colour would be scored using the Common score.
Common may be used in concert with other scores. For example, if a species of plant usually has blue flowers but occasionally has red flowers, then the state blue would be scored Common and the state red would be scored Rare.
For numeric features, Common and Rare values are coded by entering ranges of numbers in the Numeric Coding dialog box. See the topic Scoring numeric features for more details.
Rare
Rare is used to record that a state occurs uncommonly or rarely in an entity.
Rare will usually be used in concert with other scores. For example, if a species of plant usually has blue flowers but occasionally has red flowers, then the state blue would be scored Common and the state red would be scored Rare.
Note that Rare should be used only in the case where a state occurs rarely in an entity, not in the case that the entity is rare. If a state always or usually occurs in a rare entity, you should still use the Common score.
In the Lucid Player, Rare is used to rank the list of Entities Remaining. If entity e is scored Rare for state s, then e will be moved down the list of Entities Remaining (List Mode) when the user chooses s (compared with other entities that are scored Common for s). Hence, if Rare is widely used in a key and at the end of an identification several entities remain, entities at the top of the list are more likely to be correct than entities at the end of the list.
For numeric features, Common and Rare values are coded by entering ranges of numbers in the Numeric Coding dialog box. See the topic Scoring numeric features for more details.
Uncertain
Uncertain is used to record that the key author is uncertain or does not know whether a given state occurs or does not occur in a given entity.
Uncertain will sometimes be applied to all states of a feature and sometimes only to one or a few states of a feature. For example, consider a key to plants which includes a feature referring to the colour of the fruit. It may be that one species in the key is known only from a few specimens and fruits have never been observed. In that case, all the states of the Fruit colour feature would be scored Uncertain. Another species may be poorly known and yet it is clear that the fruits are not white or coloured, but they could be black or dark grey. In that case, white and the coloured states could be scored Absent and dark grey and black both scored Uncertain.
In the Lucid Player in normal identification mode, Uncertain is treated the same as Common. That is, if an entity e is scored Uncertain for state e will remain in Entities Remaining when a user chooses s. This is appropriate behaviour for an identification, as e should not be falsely discarded if a key user has more information about it than was available to the key developer.
The behaviour of the Player can also be changed by un-checking the Retain Uncertains menu option, in which case Uncertain is treated the same as Absent. This would be appropriate if a user of the key is querying the Player to return a list of all entities known to have state s (rather than all entities that may have s).
For numeric features, Uncertain is coded as a special value in the Numeric Coding dialog box. See the topic Scoring numeric features for more details.
Present by Misinterpretation, and Rarely Present by Misinterpretation
While the Uncertain score in Lucid is used to capture uncertainty by the key developer, the Present by Misinterpretation scores are used to preempt likely uncertainty or mistakes by a key user.
Consider a key to fish with a feature Number of dorsal fins and the states one dorsal fin and two dorsal fins. Some species of fish clearly have a single dorsal fin, while others clearly have two dorsal fins. Angler fish have two dorsal fins, but the first is modified into a fleshy lure that does not look like a normal fin. In this case a user of the key may misinterpret an angler fish as having a single dorsal fin. If angler fish were scored correctly as having two dorsal fins many users would make a mistake at this point. Conversely, scoring angler fish as having a single dorsal fin (to account for the likely mistake) would introduce erroneous coding into the key.
In Lucid the Present by Misinterpretation scores are used to account for likely user mistakes while maintaining the integrity of the data. In the case of angler fish, the state two dorsal fins would be scored Present, and the state one dorsal fin would be scored Present by misinterpretation.
Lucid Builder Present by Misinterpretation score example
In the Lucid Player in normal identification mode, Present by Misinterpretation is treated the same as Common. That is, if an entity e is scored Present by Misinterpretation for state s, then e will remain in Entities Remaining when a user chooses s. This is appropriate behaviour for an identification, as it pre-empts ebeing discarded when a user makes a common and predictable mistake.
The behaviour of the Player can also be changed by un-checking the Allow Misinterpretations menu option, in which case Present by Misinterpretation is treated the same as Absent. This would be appropriate if a user of the key is querying the Player to return a list of all entities that truly have one dorsal fin (rather than all entities that may appear to have one dorsal fin).
The Rarely Present by Misinterpretation score is used to encode a case where it is occasionally the case that a state could be misinterpreted as being present. For example, a species of fish may normally clearly have two dorsal fins, but in occasional specimens one dorsal fin may be reduced to a small spine that could be overlooked. In the Lucid Player with Allow Misinterpretations check-marked, a Rarely Present by Misinterpretation score is treated the same as a Rare score; with Allow Misinterpretations unchecked, Rarely Present by Misinterpretation is treated the same as Absent.
Lucid Builder Present by Misinterpretation with other another score example
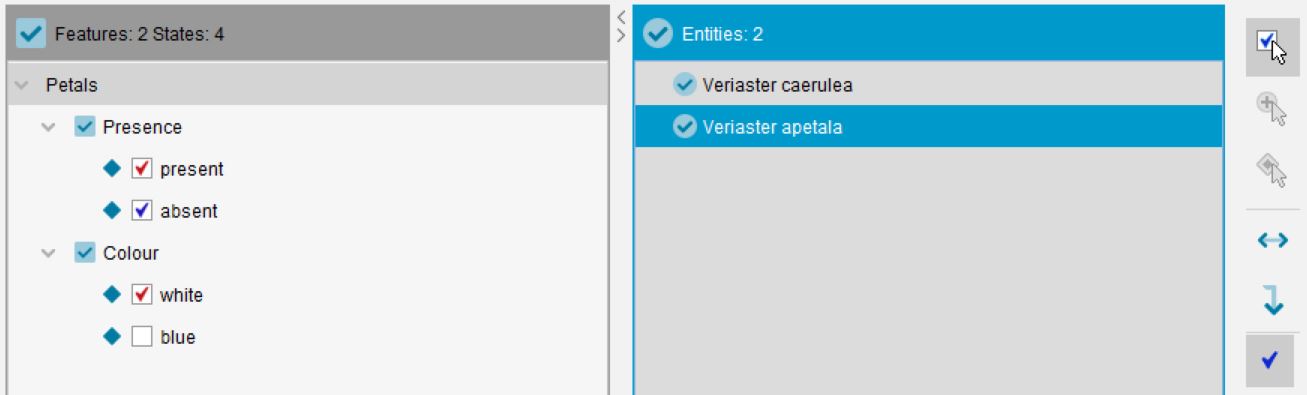
Note that the Present by Misinterpretation scores are usually used in concert with other scores, as in the case above. Sometimes, however, Present by Misinterpretation or Rarely Present by Misinterpretation may be used alone, especially when a feature is controlled by a dependency. For example, consider a key to plants with the features Petals (with states present and absent) and Petal colour (with states white and blue). A species of plant in the key may lack petals but have white, petal-like bracts around the flower which could be misinterpreted as petals. This species would be coded as Common for the state Petals: absent, Present by misinterpretation for the state Petals: present and Present by misinterpretation for the state Petal colour: white.
For numeric features, the By Misinterpretation score is set as an annotation for a range of numbers in the Numeric Coding dialog box. See the topic Scoring numeric features for more details.
Not Scoped
The Not Scoped score in Lucid is used to enable coding of features that are useful and applicable only for a subset of the entities in the key. In the Lucid Player, features scored using Not Scoped are initially hidden, and are inserted into the Features Available list only when they become applicable to the identification.
Consider a large key with 1000 Entities. It will be appropriate to score some features for all the entities, using the normal Lucid scores (Absent, Common, Rare etc.). But consider a feature that is useful for identification only in a small subgroup of the entities, and which is inapplicable, ambiguous or insufficiently known for the bulk of entities. In Lucid, the entities in the subgroup can be coded for the feature, but all the other entities (not in the subgroup) will be given the Not Scoped score for that feature. In the Lucid Player, the feature will only become available when the list of Entities Remaining includes only entities that are scored for the feature using normal scores.
To explain the Not Scoped score further, consider a key to fishes with the following Entities and Features:
Features
Entities
Body shape in cross-section
Rounded
Laterally
flattened
Dorsoventrally
flattened
Paired spots along flank
Adjacent,
forming figures of eight
Separated
by a thin line
Barracuda
Bluefin Tuna
Red Gurnard
Sand Mullet
Spotted Weedfish
Crested Weedfish
…etc*
*The key also includes many other species of fishes.
The feature Body shape in cross-section can be scored for all the fish in the key, and it would be good practice to do so. The feature Paired spots along flank, however, is very useful to distinguish the two species of weedfish, which are otherwise difficult to separate, but is difficult to answer unambiguously for most other species of fish (some other species may also have paired spots in various arrangements on the flank, but for these other species the pattern of spots is not a useful feature for identification).
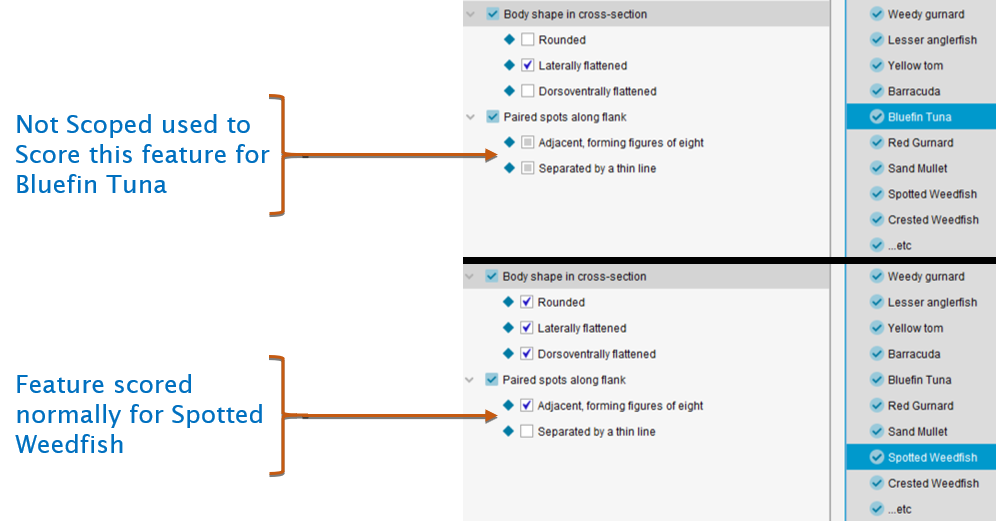
In this key, it may be important to be able to make use of the feature Paired spots along flank to separate the weedfish, but it would be difficult or impossible to score it for all fish. The Not Scoped score would be used in this circumstance. For all species other than the weedfish, both states of Paired spots along the flank are given the score Not Scoped, while for the weedfish the feature is scored using the normal Lucid scores. The figure below shows the coding for two species as it would appear in the Lucid Builder
Lucid Builder Not Scoped scoring example
In the Lucid Player, when the key is started the feature Paired spots along flank is initially hidden. As a user of the key addresses the available features, the list of entities becomes progressively reduced. It may be that, at some point in the identification, only weedfish remain in Entities Remaining. All the weedfish are scored for the feature Paired spots along the flank, so at this point the feature is inserted into Features Available and can be used to help discriminate the species of weedfish.
For multi-state features, the Not Scoped score is automatically assigned to all the states of a feature – it cannot be given to a single state.
Common – the state occurs commonly (or always) in the entity.
Rare – the state occurs rarely in the entity.
Uncertain – it is not known whether the state occurs in the entity or not
Common and Misinterpreted – the state does not occur in the entity, but it could be commonly misinterpreted that it does.
Rare and Misinterpreted – the state does not occur in the entity, but it could be misinterpreted that it does, though only rarely.
Not Scoped – all states of the feature are not scored and will not be scored for the entity.
Numeric features in Lucid may be scored using four possible scores:
Numeric absent – the numeric feature does not occur in the entity
Normal – the numeric feature occurs normally in the entity
Misinterpreted – the numeric feature does not occur in the entity, but it could be misinterpreted that it does.
Uncertain – the value for the numeric feature for the entity is not known.
Not Scoped – the numeric feature is not scored and will not be scored for the entity
Note
Normal, Misinterpreted and Uncertain numeric scores are set and distinguished via the Numeric Score Dialog not within the item trees.
Once a numeric Feature has been scored the icon changes to bold.
Scoring
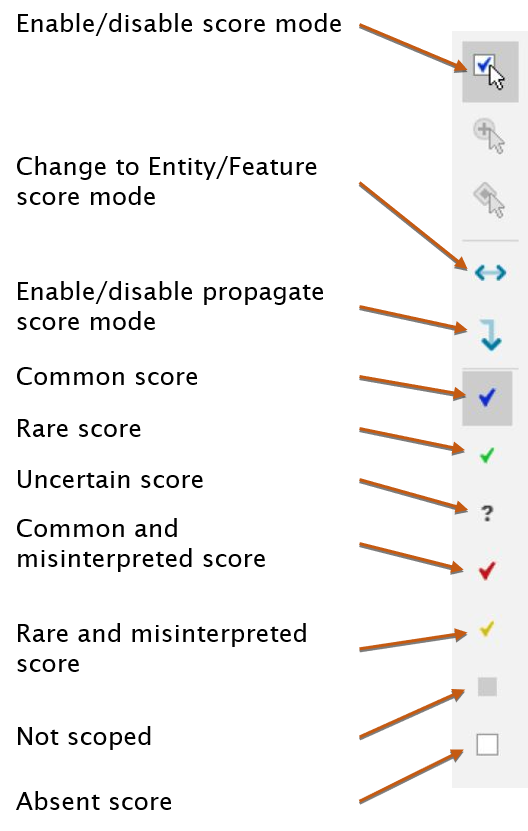
Scoring multi-state features in the Features and Entities panels
The simplest way to score entities and features in the Lucid Builder is to click the Enable Score Mode button to the right of the Entities panel. If the currently active selected item is an entity, score boxes will appear in the Features tree; if the currently active selected item is a state, score boxes will appear in the Entities tree. At any time you can flip between scoring entities for a state, or states for an entity, by clicking on the Change Score Mode button.
Tip
If a Feature node is selected in the Features tree instead of a state node, clicking on the Enable Score Mode button will place the Entities tree into score mode but no score boxes will appear. In this case, select a state in the Features tree. Similarly, if nodes of the Features tree are closed so no states are visible, clicking on Enable Score Mode with an entity selected will place the Features tree into score mode but no score boxes will appear. In this case, open nodes in the Features tree to display some states.
When the Lucid Builder is placed in score mode, a series of buttons providing the different possible scores will appear to the right hand side of the Entities panel.Choose the appropriate score by clicking on one of the score buttons, then click on one or more score boxes in the Features or Entities panels.
Scores can be changed at any time, simply by choosing a different score and clicking on a scored box again.
Note that the Not Scoped score can only be applied to all states of a feature. If the Not Scoped score is selected, clicking on the score box for any state will set all states of the feature to Not Scoped. Conversely, if the states of a feature are currently coded using Not Scoped, giving any other score to one state will cause all other states to be given the Absent score.
Score propagation
If your key has an Entity hierarchy it is possible to have the Lucid Builder propagate an applied score to a parent entity to propagated down to all the children. The score propagation option can be toggled on or off depending on your needs via the Propagate score mode button on the Score toolbar. Alternatively, if you only wish to enable score propagation temporarily you can hold down the Control (ctrl) key when you apply a score to a parent Entity.
Warning
Any score applied to the parent Entity, while Score Propagation is enabled, will overwrite any scores that have already been applied to the child Entities. You can override the propagated score with another score value at anytime. If you mistakenly override scores to child Entities use Undo (ctrl + z) to revert back to the original scores.
Scoring multi-state features in the Score Spreadsheet
Scoring in the Features or Entities trees provides a view of all state scores for one entity, or all entity scores for one state. The Spreadsheet Scoring panel allows you to see all scores arranged into a handy spreadsheet, with entities as columns and states as rows.
To use Spreadsheet score mode, click the Spreadsheet Scoringtab at the base of the tree panels.
Lucid Builder Spreadsheet scoring tabLucid Builder Spreadsheet scoring example
To score, select the scoring type needed from the scoring buttons to the right, then click the scoring box corresponding to the entity and feature you wish to score.
The feature list can be expanded or contracted by clicking the plus or minus buttons located next to the parent items or by using the expand all and collapse all buttons in the main toolbar.
Spreadsheet “bulk” Scoring
Where common scores apply to a number of entities listed next to each other or character states you can use “bulk score” functionality. Use the context menu (mouse right click) to mark the start cell, then move the pointer to the last cell across where you wish to apply the scores, you will see the range of cells to be scored highlighted pink, then click to score the cell. All cells between the selected cells will take on this new score value. This same technique can be also used to un-score or change scores in cells. It can also be applied across multiple rows. You can exit bulk scoring mode using the escape key.
Display settings in the Spreadsheet Scoring panel are set through the Builder Preferences dialog box.
See the topic Configuring the Lucid Builder for more information.
Scoring numeric features
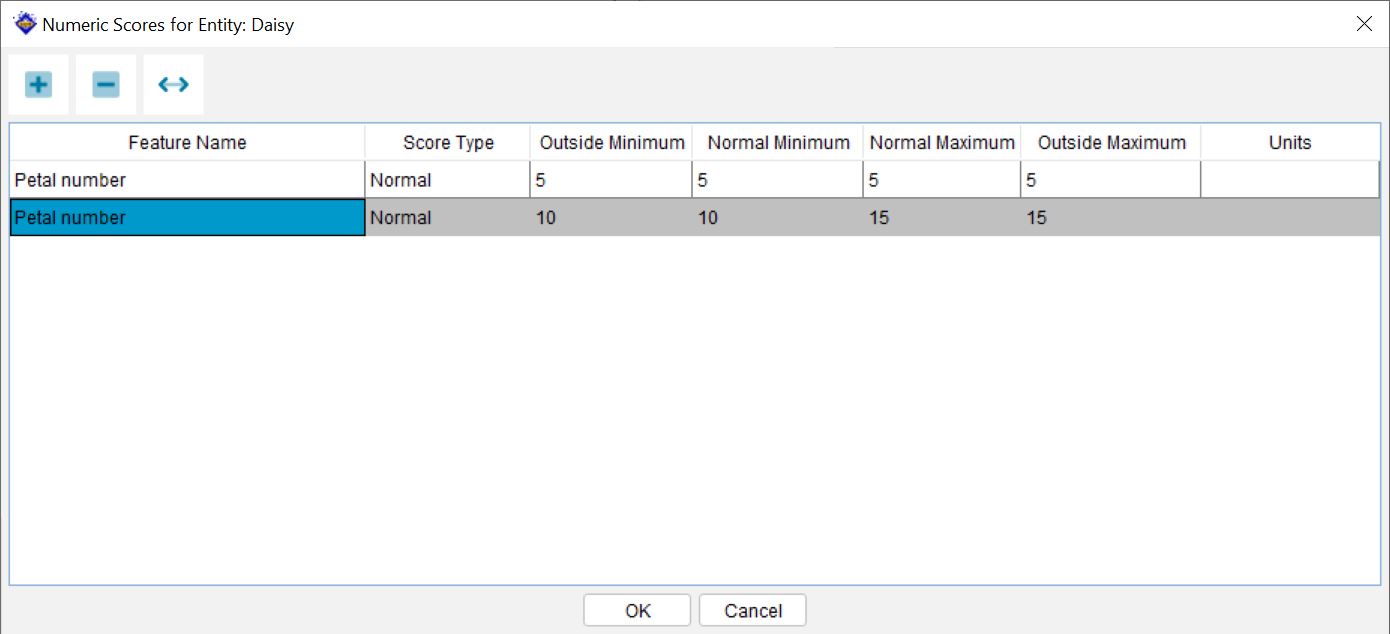
In score mode in the Features or Entities trees or in the Spreadsheet Scoring panel, numeric features are shown with a hash symbol in the score box . Clicking on a numeric feature’s score box will open the Numeric Scores panel. In this panel, enter the values that the entity can have for the feature.
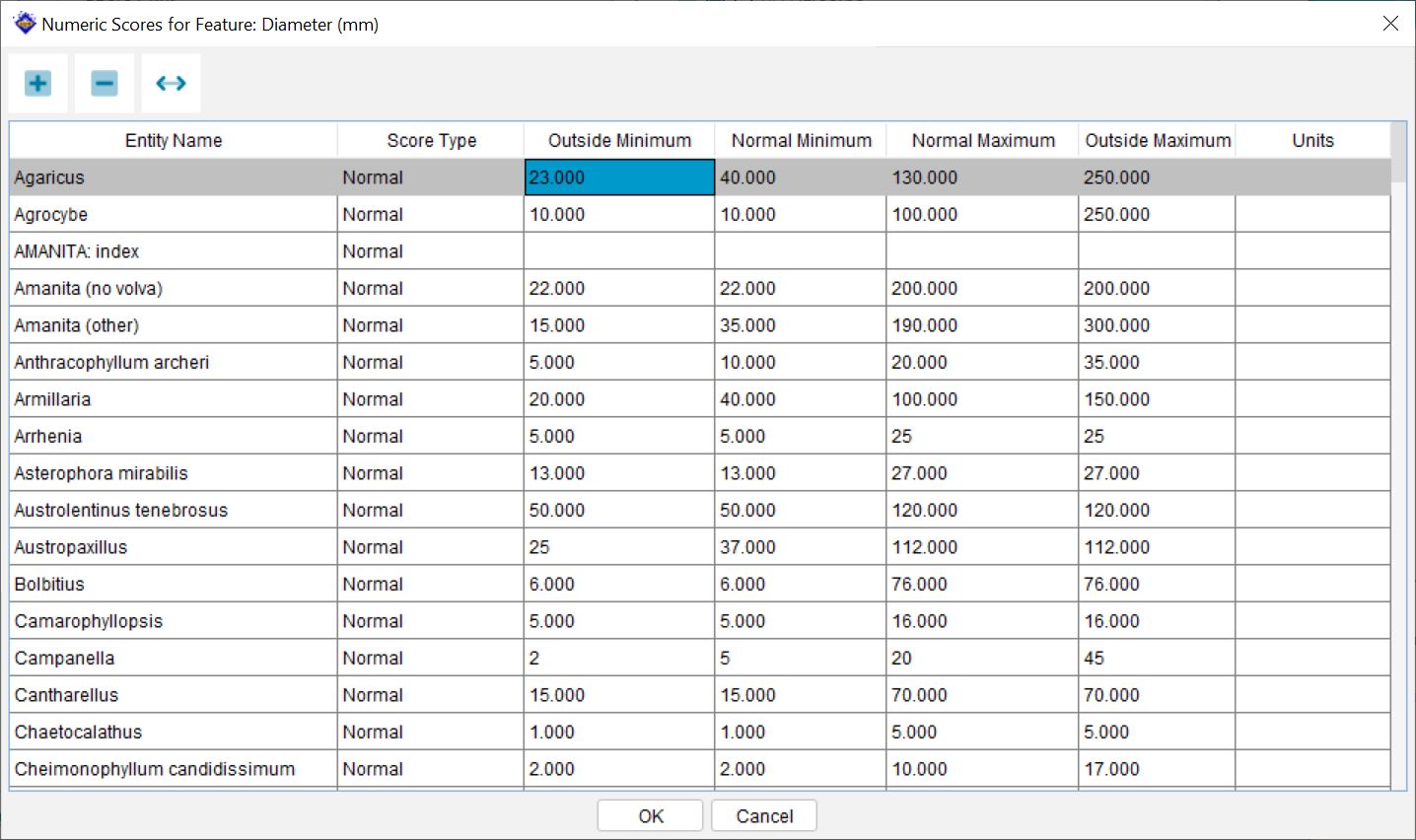
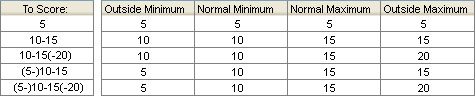
Four values may be entered – for the outside minimum, normal minimum, normal maximum and outside maximum. Think of the outside scores as rare ranges and the inside as a normal range. For instance, a plant may have leaves that are normally 10-20 mm long, but are occasionally as low as 8 mm or as high as 25 mm. In text, this is often written (8-)10-20(-25). In the dialog box, use 8 for Outside Minimum, 10 for Normal Minimum, 20 for Normal Maximum and 25 for Outside Maximum.
It is not necessary for all these values to be different. The following table gives some examples of valid scores:
Note
Sometimes a taxon will need to be scored with a disjunct range. For instance, consider a plant that may have 5 or 10-15 petals. In this case, click on the Add Numeric Record button in the Numeric Features panel. A new row will be inserted into the Numeric Scores panel. Score the two (or more) disjunct ranges in separate rows:
Numeric Scoring disjunct range example
The Score Type column in the Numeric Scores panel can be used to assign numeric scores of type Normal, Uncertain and Misinterpreted.
Use Normal when the values entered are normal for the entity being scored. This is equivalent to the Normally Present and Rarely Present scores for a multi-state feature.
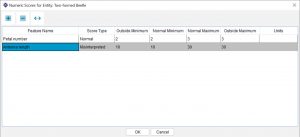
Use the Misinterpreted score type when you are scoring a numeric range for a Feature that may be misinterpreted as being present. For example, a key to insects may include a species that has very small antennae, but large antenna-like structures that could be misinterpreted by a user as being antennae. In this case record the length of the real antennae using a Normal numeric score, and record the length of the antenna-like structures using a Misinterpreted numeric score:
Numeric Scoring Misinterpreted example
In this way, a key builder can preempt a mistake made by a user measuring the length of the pseudo-antennae instead of the real antennae.
Use the Uncertain score type to record that a value for a numeric feature is currently unknown.
For more information on the way Misinterpreted and Uncertain scores are handled in the Lucid Player, see How to use the Lucid scores.
Numeric Precision
It is recommend that you maintain a consistent precision level through the scoring of numerics. Take the following example,
Festuca occidentalis, with scored anther lengths of (1) 1.5 – 2.5 (3) mm
A user of the key enters the following value for the anthers in the Player of 0.5-0.6
Because of the difference between precision on the first compared anther value (1) for Festuca occidentalis, Lucid rounds the 0.5 to 1, leaving Festuca occidentalis in the entities remaining. If the precision level was set to (1.0) then no rounding would occur and Festuca occidentalis would be discarded as a match.
Some types of edits to a key (such as adding or deleting items in the trees, scoring and changing feature types) may be undone by pressing Ctrl-Z or choosing Undo from the Edit menu
The following operations may be undone:
Add Item
Delete Item
Rename Item
Change Item Type (e.g. Feature/State)
Change Feature Type (Grouping/Multistate/Numeric)
Cut
Paste
Drag and Drop
Set Score
Clear Score
The undo history is limited to 200 edits. As additional edits are performed the undo edits at the tail of the queue are removed.
The following operations reset the undo history:
New Key
Open Key
Open Recent Key
Import Key (LIF/LIF3)
Import Item Lists (Feature/Entity)
Any changes made prior to performing these operations cannot be undone or redone.
Operations undone using Ctrl-Z may be redone by pressing Ctrl-Shift-Z or choosing Redo from the Edit menu.
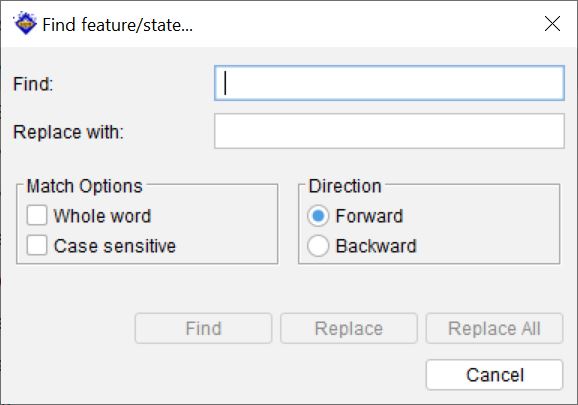
To search for a feature or state, activate the Features panel by clicking within it, then choose Find feature/state from the main menu.
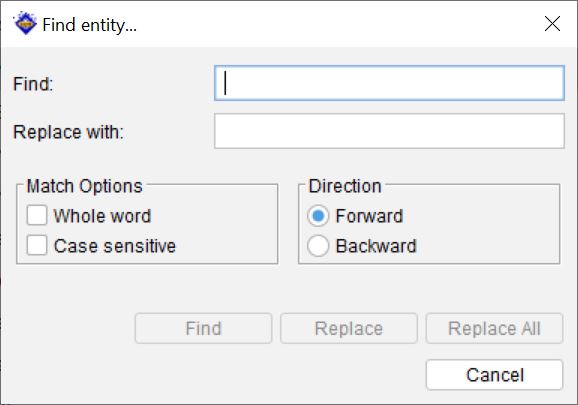
To search for an entity, activate the Entities panel by clicking within it, then choose Find entity.
In the Find dialog, type the text to search for in the Find text box. Set the direction of the search using the Forward or Backward radio button options to specify a direction to search from the currently selected item.
The Match Options allow for a case sensitive search and/or to only match on whole words.
To replace existing text enter the find text along with the replacement text in the Replace With text box. Then to selectively replace text use the Find button followed by the Replace button. Alternatively use the Replace All button to replace every instance found of the Find What text.
Tip
The Find function can also be invoked using the keyboard shortcut Ctrl+F or the Find button on the main button bar.
Items in the Features and Entities trees may be deleted at any stage by selecting the item and pressing the Delete key, using the Delete button on the toolbar or choosing Delete from the Edit menu.
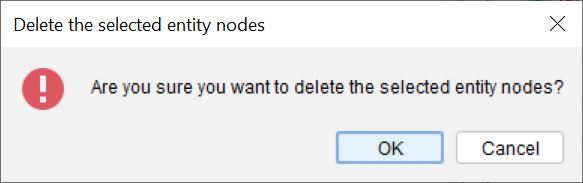
If the Builder Preferences option Prompt for confirmation during tree delete operations is checked, a Confirm Delete dialog will appear, to confirm that the operation should go ahead.
Lucid Builder Delete Entity confirmation dialog
If Prompt for confirmation during tree delete operations is unchecked, the item will be deleted immediately without confirmation.
The selected item will be deleted from the key.
Tip
This operation can be undone via the undo operation (ctrl + z).
Warning
If an item to be deleted has children, all descendents will be deleted along with the selected item.
You may also delete several items at a time, by selecting multiple items before choosing Delete:
To select a contiguous range of items, select the first item then hold down the Shift key and select the last item in the range.
To select a non-contiguous range of items, hold down the Control key while selecting each item.